
外观
工作流思路
- 1.工作流设计
- 2.工作流流程记录表
- 写入该业务的流程 针对业务修改
在发起借阅申请时,写入借阅记录 + 该业务的所有的工作流节点(好像会冗余? ) => 只记录审核的状态,意见 (需要根据当前借阅数据的密级决定启用哪一个工作流) 工作流又如何确定走向呢,目前的节点存放都是有过渡线的(一次性查出来再处理!) 如果一次性查出来,如果记录已经审核的状态?
是否需要借阅记录存放当前节点 (表里加个是否需要审核字段=> 改为审核状态字段(无需审核、已驳回、已撤销申请、已通过审核)),记录当前节点)
工作流引擎开发
- 发起 应当传入流程id,表单数据 ;对应生成节点的记录,直到待审核或时间之类的等待的activity/records
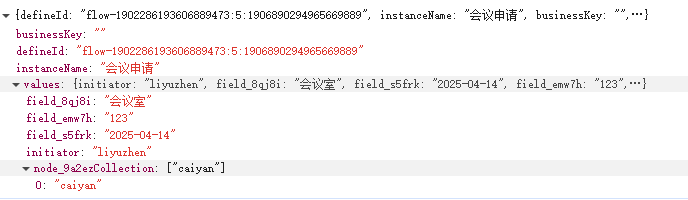
设计:
define
- save 保存
- 问题1 json字符串的序列化反序列化的保存
- pulish:发布 - post更新,版本服务端+1
- start:发起流程
- 发起之后应该生成activity 活动 包含开始与结束
instance
状态
- 进行中
- 通过
- 拒绝
- 撤销
activity:工作流的活动
- records:根据流程读取活动记录
task
- todo 获取代办列表
- complete:审核工作流
- 需要传入comment(审批内容实体)
- 包含附件
- 需要传入comment(审批内容实体)
- comment 根据活动id获取评论
接口定义
- 保存:保存当前
- 发布:更新内容及版本
数据库与 JSON 映射
现有实体已适合存储工作流数据,以下是各表的作用:
- WorkflowDefinitions:存储工作流定义的 JSON(Data)及元数据(如 WorkflowName、IsEnable)。
- WorkflowInstances:记录工作流实例的状态(Status、SubStatus)和运行时 JSON(Data)。
- WorkflowExecutionRecords:记录每个节点的执行状态,包括节点 ID、类型、负责人和完成时间。
- WorkflowTask:管理分配给用户的任务,包括任务状态、负责人和截止时间。
建议优化:
- WorkflowDefinitions.Data 保存 JSON 结构,用于定义工作流。
- WorkflowInstances.Data 可存储运行时状态(如当前节点、变量)。
- WorkflowExecutionRecords 记录每个节点的执行详情(开始/结束时间、结果)。
- WorkflowTask 管理任务分配和状态。
3. 工作流执行逻辑
以下是工作流执行和状态管理的分步方案:
步骤 1:初始化工作流实例
当用户发起工作流时:
- 创建 WorkflowInstances 记录:
- 设置 WorkflowDefinitionsId 为对应 WorkflowDefinitions 的 ID。
- 生成唯一的 WorkflowInstancesNo(如时间戳+UUID)。
- 设置 WorkflowInstancesName 为工作流名称或用户输入。
- 设置 Status 为“Started”,SubStatus 为“Initiated”。
- 将 WorkflowDefinitions.Data 复制到 WorkflowInstances.Data。
- 为 root 节点创建 WorkflowExecutionRecords:
- 设置 WorkflowDefinitionId、WorkflowInstanceId 和 WorkflowNo。
- 设置 NodeId 为“root”,NodeName 为“发起人”,NodeType 为“root”。
- 设置 Status 为 1(已完成),EndTime 为当前时间。
- 为第一个审批节点(node_r2izq)创建 WorkflowTask:
- 设置 DefinitionId、InstanceId 和 Name(“审批人”)。
- 设置 Assignee 为 JSON 中的 users(如“caiyan”)。
- 设置 Status 为 0(待处理),StartTime 为当前时间。
- 若 timeout.enabled = true,设置 DueDate 为 24 小时后。
步骤 2:处理节点流转
对每个节点执行以下逻辑:
- 获取当前节点:
- 从 WorkflowInstances.Data 或 WorkflowExecutionRecords 获取当前节点(Status = 0 的最新节点或 JSON 中的 next 节点)。
- 执行节点:
- 审批节点(如 node_r2izq、node_9txlo):
- 根据 assigneeType(“user”或“self”)分配任务给用户(如“caiyan”或“nietingting”),若为 self 或 leader,动态解析负责人。
- 在任务提交时,验证 formProperties(如 field_osoct 必填)。
- 根据用户操作处理 operations:
- 完成:更新 WorkflowTask.Status = 1,WorkflowExecutionRecords 设置 Status = 1 和 EndTime,流转到下一节点。
- 拒绝:更新 WorkflowInstances.Status 为“Rejected”,记录操作,终止流程。
- 委派/转交:更新 WorkflowTask.Assignee,为新负责人创建任务。
- 退回:返回上一节点,创建新任务并更新记录。
- 若 multi = "joint",确保所有负责人完成任务(multiPercent = 100)。
- 若 timeout.enabled = true,检查任务是否超过 timeout.duration(24小时),执行 timeout.action(如“pass”)。
- 通知节点(如 node_61si0、node_ndlex):
- 根据 subject 和 content 发送通知(如“节点以已审批”)。
- 自动完成节点,设置 WorkflowExecutionRecords.Status = 1。
- 记录节点信息(NodeId、NodeName、NodeType)。
- 结束节点:
- 更新 WorkflowInstances.Status 为“Completed”,FinishedAt 为当前时间。
- 创建 WorkflowExecutionRecords 记录(Status = 1)。
- 审批节点(如 node_r2izq、node_9txlo):
- 更新状态:
- 更新 WorkflowInstances.SubStatus 为当前节点 ID(如“node_r2izq”)。
- 将表单数据或变量存储在 WorkflowTask.Variables 或 WorkflowInstances.Data。
步骤 3:处理特殊情况
- 超时:
- 对 timeout.enabled = true 的审批节点,检查 WorkflowTask.DueDate。
- 若超时,执行 timeout.action(如“pass”自动流转)。
- 多人任务:
- 若 multi = "joint",跟踪所有 WorkflowTask,在 multiPercent = 100 时更新 WorkflowExecutionRecords。
- 无人处理:
- 若 nobody = "pass",无人分配时自动完成节点。
- 操作支持:
- 支持 addMulti(添加负责人)、minusMulti(移除负责人)、retract(撤回)等操作。
- 表单验证:
- 确保 formProperties(如 field_osoct)在任务完成前满足要求。
步骤 4:记录执行历史
- 每个节点处理时:
- 创建 WorkflowExecutionRecords:
- 设置 NodeId、NodeName、NodeType(从 JSON 获取)。
- 设置 Assignee(从任务或 JSON users 获取)。
- 设置 Status(0=待处理,1=完成)。
- 计算 Duration(EndTime - StartTime)。
- 存储节点数据(如表单输入)在 Data 中。
- 创建 WorkflowExecutionRecords:
- 更新 WorkflowTask:
- 完成时设置 EndTime 和 Duration。
- 存储表单数据或变量在 Variables 中。
0806 优化审核引擎
独立封装引擎状态机模式 流程:
- 建立流程上下文对象
- 建立节点处理器每一个节点对于一个处理器
_nodeHandlers = new Dictionary<string, INodeHandler>
{
{ "start", new StartNodeHandler() },
{ "approval", new ApprovalNodeHandler() },
{ "exclusive", new ExclusiveNodeHandler() },
{ "notify", new NotifyNodeHandler() },
{ "cc", new CcNodeHandler() },
{ "timer", new TimerNodeHandler() },
{ "end", new EndNodeHandler() }
};- 执行器
- 创建执行记录
- 根据节点类型获取节点处理器并执行对应节点
- 执行后更新执行记录
- 处理执行结果
- 根据节点的动作执行不同动作;
Continue, //继续执行下一节点; 开始节点 分支节点的默认分支
Wait, //等待; 审核节点
Branch, //分支 分支节点的分支 【这一步会有一个栈的操作 为了多分支】
Complete //完成 结束节点exclusive → [分支: approval] → 创建任务(保存调用栈) → 等待审核 → 审核通过 → 恢复调用栈 → 继续执行 → 回到主流程
- approval:
- 创建执行记录 → Status: Running
- 创建审核任务 → 等待人工审核
- 人工审核完成 → 更新任务状态
- 继续下一个节点 → 执行记录保持 Running(或可考虑更新为 Completed)
Elsa-Core 工作流使用
- 需要运行一个服务端
- 有工作流的引擎和设计器
- 有持久化存储
- 可以通过Dashboard监控管理工作流执行状态
服务器配置
服务器配置最主要的一点是持久化存储
首先看问题分成两部分: 一是整合SQLSugar项目与Elsa工作流,二是配置Elsa的持久化存储。 可能是在使用SQLSugar作为ORM操作业务数据,同时想要引入Elsa来处理工作流,且需要工作流的状态能持久化到数据库。 Elsa的持久化配置,特别是使用Entity Framework Core或其他数据库。比如中提到通过UseEntityFrameworkPersistence配置SQLite,而中使用Elsa.Persistence.EntityFramework.SqlServer包来支持SQL Server。展示了如何通过命令行配置SQL Server数据库。这说明Elsa的持久化主要依赖于其提供的Entity Framework Core集成,而SQLSugar本身可能处理业务数据,但Elsa的持久化需要另外配置。 接下来,和介绍了SQLSugar框架,其中提到SQLSugar支持多种数据库,如SQL Server、SQLite、Oracle,并通过配置文件设置连接字符串。但用户的问题是如何将现有的SQLSugar项目与Elsa结合,所以可能需要分别处理业务数据库和Elsa的工作流数据库,或者将两者共用同一个数据库的不同模式或表。
现在,整合的关键点可能是:在同一个项目中同时配置SQLSugar和Elsa的持久化。Elsa的持久化通常使用Entity Framework Core,而SQLSugar是另一个ORM,所以两者可能独立操作各自的数据库或同一库的不同部分。 步骤可能包括:1. 在项目中添加Elsa所需的NuGet包,特别是持久化相关的包,如Elsa.Persistence.EntityFramework.SqlServer。2. 配置Elsa使用EF Core,指定连接字符串到某个数据库(可能与SQLSugar使用的相同或不同)。3. 确保数据库迁移,创建Elsa所需的表。4. 在项目中同时配置SQLSugar的连接,处理业务数据。 例如,中的代码示例展示了在Startup中配置Elsa使用EF Core和SQLite。类似地,如果用户使用SQL Server,可以参照和中的方法,使用对应的包和连接字符串。同时,在项目中SQLSugar的配置可能是在另一个地方,比如appsettings.json,通过读取相同的或不同的连接字符串来操作业务数据表。 需要注意,Elsa的持久化和SQLSugar的业务数据存储是分开的,除非特别配置,否则它们可能使用不同的数据库或不同的ORM。因此,答案需要指导用户正确添加Elsa的持久化配置,同时保持SQLSugar的现有配置不变。 可能的矛盾点在于,是否Elsa必须使用EF Core,而用户项目使用SQLSugar。根据证据,Elsa的持久化确实需要通过其提供的EF Core集成(如所示),而SQLSugar是另一个ORM,两者可以共存。因此,项目需要同时引用Elsa的EF Core持久化包和SQLSugar,并在配置中分别设置各自的数据库连接。
总结步骤:1. 添加Elsa的EF Core持久化包;2. 在服务配置中启用Elsa的持久化,指定数据库类型和连接字符串;3. 执行数据库迁移以创建Elsa所需的表;4. 保持SQLSugar的现有配置不变,处理业务数据。可能还需要注意数据库的兼容性,比如都使用SQL Server,但存储在不同的表或库中。
- 添加elsa和核心包与持久化包
- Elsa.Core
- Elsa.Server.Api
- Elsa.Designer.Components.Web
- Elsa.Persistence.EntityFramework.SqlServer`
AddWorkflow后,访问的路径需要加上文件夹
https://github.com/elsa-workflows/elsa-core/discussions/6399
docker cp a163c15de7a2:/app/App_Data/elsa.sqlite.db ./elsa.db
运行工作流
- Elsa Studio 直接点击Run命令
- 对于我们来说无用,需要实用程序调用的方式
- 使用触发器
- HTTP Endpoint
- 定时器 Timer
- Cron表达式
- 事件 Enevt
- 使用调度工作流活动
- 使用rest api
工作流状态
- Running 运行中
- Finished 完成
子工作流状态
- Pending 待办
- Executing 正在执行
- Suspended 暂停并等待外部刺激以恢复
- Finished 完成
- Cancelled 取消
- Faulted 失败故障
从Swagger中可知分
Workflow-Definitions 工作流定义
操作被定义的工作流
开始运行工作流实例(从定义的工作流编程工作流的实例)
从工作流产生具体的工作流流水
/elsa/api/workflow-definitions/{workflow-id}/dispatch
//执行? 好像跟上面哪个功能差不多
elsa/api/workflow-definitions/{workflow-id}/execute
`ExecuteAsync`更倾向于直接执行,
`DispatchAsync`更倾向于分发请求以执行。Workflow-Instances 工作流实例
操作实际业务的工作流
工作流有一个激活策略,决定是否可以运行同一工作流 Always、Singleton、Correlation 、Correlated Singleton
Workflow-Instances 工作流实例
- 开始调度工作流
1.调用工作流定义 生成工作流实例
调用elsa/api/workflow-definitions/{workflow-id}/execute 传入Definition Id
会返回一个taskid
2.调用tasks 完成节点
调用接口/elsa/api/tasks/85da7f34f4458a26/complete 传入taskid
多个task的情况下,如何通过第二个节点?
来了,后续节点的taskid在Bookmarks表中SerializedPayload中
完事
获取具体工作流详细实例;上面的taskid就可以在这里获取
/elsa/api/workflow-instances/{id}数据库
WorkflowDefinitions:工作流定义;新建的工作流,不同版本会生成不同的记录WorkflowInstances:工作流实例运行记录;开始运行的工作流的记录WorkflowDefinitions->WorkflowInstancesBookmarks:当前正在执行的工作流 (活动节点)ActivityExecutionRecords:工作流执行记录;记录以及执行WorkflowExecutionLogRecords:工作流执行日志记录 对应Instances页面的流程图
Studio运行
本地化
Elsa-Studio项目 运行Elsa.Studio.Host.Server项目 需要先运行
#/src/modules/Elsa.Studio.Workflows.Designer/ClientLib
#/src/framework/Elsa.Studio.DomInterop/ClientLib
#把这两个项目分别执行
npm install
npm run build
#会分别输出:
#Designer -> src\modules\Elsa.Studio.Workflows.Designer\wwwroot\designer.entry.js
#DomInterop -> src\framework\Elsa.Studio.DomInterop\wwwroot\*设置多语言,在配置文件中DefaultCulture:zh-CN 完成后重新生成项目,允许就可以了
-17 22
流程图
Switch 跟代码的switch一样 匹配(13)
Event 阻止事件 (14、25)
流程决策
- Join 等待 ()
- Fork 分支 ()
RunTask
- 每一个runtask节点的payload都是单独的,payload可以从上下文/变量中获取,在调用complete中可以传递
{"result": "结果"}
- 每一个runtask节点的payload都是单独的,payload可以从上下文/变量中获取,在调用complete中可以传递
FlowFork
Delay 延时(14) Bookmark(25)
工作流定义
应该是需要从数据库查询出用户角色
工作流实例
就是在execute工作流时需要传入具体的数据比如申请的人,请假天数或者报销金额等实际的数量 在工作流中实际使用
Eg:
- 工作流定义时新增变量
VARIABLES : Object(json) - 节点
SetVariable,INPUT中设置变量名,获取ValuegetInput('Employee')return Input.Get("Employee");- 即可获取到传入的参数
RunTask节点中,Payload中返回一个变量
return {
employee: getEmployee(),
description:"描述"
}调用
# 登录记得把token复制
# 1.启动工作流,传入对象; 切记工作流定义后需要发布才会生效
/elsa/api/workflow-definitions/{id}/execute
para:{
"versionOptions": "Latest", #调用哪个版本
"input": {
"Employee": {
"Name": "Alice Smith",
"Email": "[email protected]"
}
}
}
# 2.获取工作流实例(拿到taskid 执行下一步)
/elsa/api/workflow-instances/{id}
bookmarks: [] 中会包含下一步需要操作的节点 taskid
# 3.完成具体节点
/elsa/api/tasks/{taskid}/complete
# 对应节点传入的参数,就是这个节点执行完成了 需要输出一个什么参数,可以用来判断审核通过没有之类的
{
"result": "112233"
}payload 消息体