
外观
人工智能
提示
人工智能包含机器学习;机器学习包含深度学习
人工智能人工智能, 人工越多 越智能。。
机器学习与深度学习
深度学习是机器学习的一个分支,它使用深层神经网络来处理数据,特别适合处理大规模和复杂的数据集。而机器学习包含更广泛的算法和方法,适用于各种规模和类型的数据。
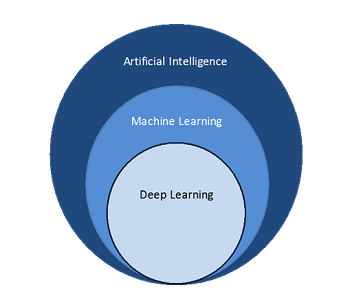
机器学习
- 人工智能的分支,是计算机从数据中学习做出预测或决策,而无需进行明确的编程,包含多种学习方法:监督学习、无监督学习、半监督学习和强化学习
- 监督学习:在这类学习中,训练数据是带有标签的。模型通过学习输入和输出之间的关系,然后应用于新的、未见过的数据,以做出预测或分类。例如,线性回归和逻辑回归就是监督学习的例子。
- 无监督学习:这类学习使用没有标签的数据。模型旨在发现数据中的内在结构和关系,例如聚类分析或降维。
- 半监督学习:监督学习和无监督学习的混合,其中部分数据带有标签,而部分数据没有。
- 强化学习:在这种方法中,模型通过与环境的交互来学习如何做出最佳决策,以达到预定的目标。模型根据其所获得的奖励或惩罚来调整其决策策略。
- 深度学习
- 通常对计资源要求较低,可以在没有特殊硬件支持的普通计算机上运行。
- 在金融风险评估、客户关系管理、推荐系统等领域有所应用
- 模型通常结构简单,易于理解和解释
深度学习
- 是机器学习的一个子集,主要依赖于一种特殊算法结构-神经网络,尤其是深层神经网络。深度学习模型通过模拟人脑的工作方式来处理复杂数据模式
- 通常需要大量的数据来训练,因为他们包含大量的参数,需要大量的数据来优化这些参数。
- 由于复杂的网络结构和大量参数,通常需要强大的 GPU 或 TPU 来加速训练过程。
- 特别擅长图像处理、语音识别、自然语言处理等领域,这些领域通常涉及大量非结构化数据。
- 模型结构复杂, 包含多个隐藏层,解释性较差,能够捕捉数据深层次特征
- 算法集合
- 卷积神经网络
- 循环神经网络:不正常数据,文本语音等集合
- 深度学习+强化学习=深度强化学习
区别
- 机器学习需要人为机器学习软件提供大量分析过具有相关特征的结构化数据
- 深度学习只需要原始数据,能出来非结构化的数据,他会自行推导特征,决定哪些数据属性权重高,能解决复杂问题
神经网络
- 神经元:最小的神经网络
- 逻辑回归模型:对神经元进行设置配置形成模型
- 神经网络训练:调整参数,使神经网络更准确
Transformer 架构
Transformer 架构是一种深度学习模型,它在自然语言处理(NLP)领域取得了革命性的进展。该架构最初由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出。与传统的循环神经网络(RNN)和卷积神经网络(CNN)相比,Transformer 架构在处理序列数据时具有显著的优势,特别是在处理长距离依赖问题时表现出色。 Transformer 架构的核心是自注意力(Self-Attention)机制,也称为内部注意力。自注意力机制允许模型在处理一个序列元素时,同时考虑序列中的其他元素,而不仅仅是前一个元素。这种机制使得 Transformer 能够捕捉序列内部复杂的关系和模式。
主要由以下几个部分组成:
输入嵌入(Input Embeddings):将输入序列的每个元素(如单词或字符)转换为固定大小的向量表示。
位置编码(Positional Encoding):由于 Transformer 没有递归结构,它无法捕捉序列中元素的位置信息。位置编码通过向输入嵌入添加额外的信息来解决这个问题,确保模型能够利用序列中元素的顺序。
自注意力层(Self-Attention Layers):这是 Transformer 的核心,它允许模型在处理一个元素时,考虑到序列中的其他元素。自注意力层由查询(Query)、键(Key)和值(Value)组成,通过计算这些元素之间的相似度来确定注意力权重。
多头注意力(Multi-Head Attention):Transformer 通过并行地执行多个自注意力操作来增强模型的表示能力。每个操作关注输入的不同部分,最后将这些信息合并起来。
前馈神经网络(Feed-Forward Neural Networks):在每个自注意力层之后,Transformer 包含一个前馈神经网络,它对每个位置的表示进行独立处理,增加模型的非线性能力。
层归一化(Layer Normalization):为了稳定训练过程,Transformer 在每个子层的输出上应用层归一化。
残差连接(Residual Connections):每个子层(自注意力层和前馈神经网络)的输出都会与其输入相加,这是为了减少深层网络中的梯度消失问题。
Transformer 架构在机器翻译、文本摘要、问答系统等多个 NLP 任务中取得了显著的成绩。此外,它还催生了一系列基于 Transformer 的预训练模型,如 BERT、GPT、XLNet 等,这些模型在各种 NLP 任务中都取得了突破性的表现。
cnn图像分类算法(错误率从低到高)
- NASNet(
4%) - Inception-V4
- ResNet-152
- GoogNet(
10%) - VGG
- AlexNet
- SIFT+FVS(
25%)
YOLO(You Only Look Once)和CNN(Convolutional Neural Network)都是深度学习在计算机视觉领域的应用,但它们在目标检测任务中扮演的角色和工作原理有所不同。
CNN(卷积神经网络)
CNN是一种深度学习模型,主要用于图像识别和分类任务。它通过多层卷积层和池化层自动学习图像的特征表示,并通过全连接层进行分类。CNN的关键优势在于其能够捕捉图像的局部特征,并通过层级结构学习更抽象的特征表示。典型的CNN模型包括AlexNet、VGG、GoogLeNet等。
YOLO(You Only Look Once)
YOLO是一种实时目标检测算法,它的核心思想是在单次前向传播中同时预测图像中的多个目标的位置和类别。YOLO将输入图像划分为多个网格,每个网格负责预测中心点落在该网格内的目标。YOLO通过CNN提取特征,并将目标检测任务转化为回归问题,从而在保持较高检测精度的同时实现快速的检测速度。
YOLO与CNN的主要区别
目标任务:CNN主要用于图像分类,即将整个图像分配给一个类别;而YOLO用于目标检测,即识别图像中多个目标的位置和类别。
工作原理:CNN通常通过多层特征提取后,使用全连接层进行分类;YOLO则是在一个网络中同时进行目标的定位和分类,它将目标检测视为一个回归问题,输出边界框和类别概率。
速度与精度:YOLO特别强调速度,适合实时目标检测;而传统的CNN在目标检测中可能需要更多的计算资源,速度较慢,但在图像分类任务上精度很高。
网络结构:YOLO的网络结构专门为目标检测设计,包括预测边界框、类别概率和置信度;而CNN的结构通常是为了学习图像的高级特征表示。
训练和推理:YOLO通过一次前向传播完成整个目标检测过程,这使得其推理速度非常快;CNN在目标检测中的应用通常需要额外的步骤,如区域建议网络(Region Proposal Network),这增加了训练和推理的复杂性。
总结来说,YOLO是一种基于CNN的目标检测算法,它利用CNN的特征提取能力,并通过特定的网络设计实现了快速且准确的目标检测。而CNN则更多地用于图像的分类任务,并且在目标检测中通常作为特征提取的一部分。
语义分割
对图像中的每个像素进行分类,即确定每个像素属于哪个类别(例如,人、汽车、建筑物等)。它输出的是一个像素级别的分类图,每个像素都被标记为属于某个类别。
提示
显卡基础:
- 架构:相当于运行布局,布局越好跑的越流畅。
- 工艺:制程越小精度越高,越能发挥更多性能。
- 光栅以及流处理器:相当于劳动力,人越多执行力越强。
- 核心频率:反应速度,相当于跑车百米提速效率。
- 显存频率:相当于限速标志,决定了最大运行速度。
- 显存位宽:相当于划线,决定了最大运行通道。
- 显存容量:相当于道路限宽,决定了最大承载量。