
外观
mysql常用
安装
mysqld --initialize #初始化
mysqld -install mysql5.7 --defaults-file="c:\mysql5.7\my.ini" #指定服务名
mysqld -install servicesname
net start servicesname
#mysql initialize 初始化一个密码, 在data/*.err
mysql -u root -p #登录之后
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
SELECT user,host FROM mysql.user;登录异常可参考[[MySql执行语句常见问题#ERROR 1045 (28000) Access denied for user 'root'@'localhost' (using password YES) MySQL密码正确却无法本地登录]]>
日常命令
--查看表字段
DESCRIBE [表名]
-- 清空表
TRUNCATE talbe [表名];
DELETE FROM [表名];
-- 新增、修改字段
alter table [表名] add [字段名] 类型
alter TABLE [表名] MODIFY [字段名] VARCHAR(100);
alter table [表名] change 原字段名 新字段名 类型备份
日常备份命令
# 推荐:日常备份单库时使用 -B
mysqldump -u root -p --single-transaction -q --default-character-set=utf8mb4 -B wy_oa2 | gzip > wy_oa2_$(date +%Y%m%d).sql.gz
# 还原时直接导入(到处有-B 无需建库)
gunzip -c wy_oa2_20240601.sql.gz | mysql -u root -p --default-character-set=utf8mb4
#指定数据库
gunzip -c wy_oa2_20240601.sql.gz | mysql -u root -p --default-character-set=utf8mb4 wy_oa2备份命令详解:
# 全量备份 系统层面执行,不用进入sql命令行
mysqldump -u root -p stumdb>c:\学号.sql # mysqldump不能登陆数据库操作
<db> table1 table2 #指定备份哪些表
--default-character-set #字符集 一般中文使用:utf8mb4 防止中文乱码
-h #主机地址
-P #端口号
-B,--databases #备份多个数据库会 -B db1,db2【包含创建语句,所以单库也可以用这个 还原的时候会自动建库了】
# mysqldump -B db1 db2
-t,--no-create-info #仅备份数据 不会备份表结构 【也就是没有create table语句】
-d,--no-data #仅备份数据
--compact #精简输出 无注释和set语句
-c,--complete-insert #完整的insert语句,默认的没有列名
-e,--extended-insert #合并多条insert语句为单条 --skip-extended-insert没行数据一条insert
--quick, -q #快速加载
--opt #默认开启的 它包含了一下参数
--add-drop-table # 每个表前添加 DROP TABLE IF EXISTS 语句
--add-locks # 备份时给表加锁(LOCK TABLES),恢复时解锁(UNLOCK TABLES)
--create-options # 导出 CREATE TABLE 语句时包含所有表属性(如引擎、字符集、自增等)
--disable-keys # 恢复时先禁用非主键索引,导入数据后再启用(加速导入)
--extended-insert # 使用多行 INSERT 语句(而非单行),减少 SQL 语句数量
--lock-tables # 备份前锁定所有表(MyISAM 表保证一致性,InnoDB 建议用 --single-transaction)
--quick # 边查边输出,不把结果集加载到内存(核心内存优化)
--set-charset # 导出文件开头添加 SET NAMES 语句,保证字符集一致
--hex-blob blob/Binary字段转为十六进制 防止二进制乱码
#--ignore-table=[数据库名].[表名1] #排除指定表 格式为 `数据库名.表名`,不能只写表名
#--ignore-table=[数据库名].[表名2]
#--routines,-R #导出存储过程/函数
#--taiggers #导出触发器,默认开启的 使用--skip-triggers禁用
#--where #按条件导出部分数据 --where="created_at > '2024-01-01'"
#--single-transaction #一致性快照,避免锁表 用于生产环境备份
#--lock-tables, -l #备份前缩表 默认开启的 [使用--skip-lock-tables禁用 但需配合--single-transaction]
#生产环境黄金组合
mysqldump --single-transaction --quick --lock-tables=false db > backup.sql备份还原
# 全量还原 系统层面执行,不用进入sql命令行
mysql -u root -p [新数据库名称] < backup.sql
-h, --host #指定mysql主机的访问地址
-P #端口号
--default-character-set=utf8mb4 #字符集
--one-database #禁止在还原途中切换数据库备份并传输备份文件到三方服务器
# 更改数据库加密连接方式
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'admin@123';
# 服务器执行备份后,将数据传输到第三方保存一份
SET FILENAME=jbland_%date:~0,4%%date:~5,2%%date:~8,2%%time:~0,2%%time:~3,2%.sql
mysqldump --single-transaction --quick --lock-tables=false -u root --password=123456 [dbname]>e:/CloundInv/bak/db/%FILENAME%
winscp.com /command "open sftp://root:[email protected]" "put e:\CloundInv\bak\db\%FILENAME% /root/sqlbak/" "exit"
# -u:指定连接MySQL服务器的用户名。
# -p:指定连接MySQL服务器的密码。注意,此选项不应该紧跟在-p后面,而应该在空格后面提供密码。例如,-p mypassword。
# -h:指定MySQL服务器的主机名或IP地址。
# --single-transaction:在可重复读事务隔离级别下执行备份,避免锁表。
# --quick:快速备份,将数据流直接输出到终端,而不是先生成一个大文件再压缩。
# --lock-tables=false:备份时不锁定表,允许读取表中的数据同时执行备份。
# -d:仅备份数据库结构,不包括数据。
# -t:仅备份数据表结构,不包括数据。
# -c:使用压缩算法进行备份。
# -e:在备份文件中包含扩展的插入语句,例如INSERT INTO语句中包括列名。
# -E:在备份文件中包含注释。
# --routines:备份存储过程和函数。
# --triggers:备份触发器。
# --events:备份事件。
# 这些参数只是mysqldump命令的一部分,有更多参数可以在mysqldump文档中找到。
# 使用--password参数:您可以使用--password参数并在其后面提供密码来避免输入密码。例如:mysqldump -u username --password=mypassword dbname > backup.sql。注意,这种方法可能会将密码暴露在命令行历史记录中。
# 使用配置文件:您可以在MySQL客户端的配置文件中存储密码,然后mysqldump将自动使用该密码。在~/.my.cnf文件中添加以下内容:
[mysqldump]
user=username
password=mypassword
# 然后,您可以直接运行mysqldump命令,例如:mysqldump dbname > backup.sql,mysqldump将自动使用配置文件中指定的用户名和密码。请注意,为了保护密码,请确保在配置文件中使用正确的文件权限。# 使用winscp备份到异地
./winscp.com /command "open sftp://root:[email protected]" "put d:\12.sql /root/sqlbak/" "exit"权限
无法做到给予所有权限后 在收回系统表的权限,只有一个一个给
-- 新增一个用户
mysql> CREATE USER 'username'@'%' IDENTIFIED BY '12345678';
Query OK, 0 rows affected (0.05 sec)
-- 更改用户据密码
ALTER USER 'username'@'host' IDENTIFIED BY 'new_password'
--修改用户连接权限 root只能本地访问
RENAME USER 'root'@'%' TO 'username'@'localhost';
--将数据库dbname的所有权限付给username 所有库*.*
mysql> grant all privileges on dbname.* to 'username'@'%';
Query OK, 0 rows affected (0.02 sec)
--撤销所有权限
mysql> REVOKE ALL PRIVILEGES ON *.* FROM 'dockeruser'@'%';
--撤销对系统数据库的权限 注意无法在给与所有权限后 撤销对系统表的权限
REVOKE ALL PRIVILEGES ON `mysql`.* FROM 'username'@'%';
REVOKE ALL PRIVILEGES ON `information_schema`.* FROM 'username'@'%';
REVOKE ALL PRIVILEGES ON `performance_schema`.* FROM 'username'@'%';
REVOKE ALL PRIVILEGES ON `sys`.* FROM 'username'@'%';
FLUSH PRIVILEGES;
-- 刷新生效
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
-- `格式:grant select on 数据库.* to 用户名@登录主机 identified by '密码'` # 5.7才可以使用
grant select,insert,update,delete on *.* to root@localhost identified by 'mysql';
--or
grant all privileges on *.* to root@localhost identified by 'mysql';
-- 然后刷新权限设置。
flush privileges;
-- 回收
revoke all privileges on *.* from 'lichao'@'localhost';eg
#新建一个用户
CREATE USER 'dockeruser'@'%' IDENTIFIED BY '12345678';
#取消他的所有权限
REVOKE ALL PRIVILEGES ON *.* FROM 'dockeruser'@'%';
#新增数据库权限
GRANT ALL PRIVILEGES ON gitea.* TO 'dockeruser'@'%';
GRANT ALL PRIVILEGES ON mtab.* TO 'dockeruser'@'%';
GRANT ALL PRIVILEGES ON test.* TO 'dockeruser'@'%';sql语句巧思
SELECT '%+' || beforehand_classification || '+%',* FROM detection_project WHERE '+200+201+202+203+204+205+206+207+208+209+210+211+212+213+214+215+217+216+218+' LIKE '%+' || TRIM(beforehand_classification) || '+%'
-- 作用类似in,起始用in写更好。 主要是思路,可以把固定的字符串列到前面聚合函数
| 函数名称 | 描述 | 常见用法示例 |
|---|---|---|
| AVG() | 返回参数的平均值(忽略 NULL 值,可加 DISTINCT 去重) | SELECT AVG(salary) FROM employees; |
| COUNT() | 返回行数或非 NULL 值的数量(COUNT(*) 计数所有行) | SELECT COUNT(*) FROM employees; |
| MAX() | 返回参数的最大值 | SELECT MAX(salary) FROM employees; |
| MIN() | 返回参数的最小值 | SELECT MIN(salary) FROM employees; |
| SUM() | 返回参数的求和(忽略 NULL 值) | SELECT SUM(salary) FROM employees; |
| GROUP_CONCAT() | 将分组中的值连接成一个字符串(可指定分隔符、ORDER BY) | SELECT GROUP_CONCAT(name SEPARATOR ',') FROM employees GROUP BY dept; |
| BIT_AND() | 返回按位与(bitwise AND) | SELECT BIT_AND(flags) FROM table; |
| BIT_OR() | 返回按位或(bitwise OR) | SELECT BIT_OR(flags) FROM table; |
| BIT_XOR() | 返回按位异或(bitwise XOR) | SELECT BIT_XOR(flags) FROM table; |
| STD() / STDDEV() | 返回标准差(人口标准差) | SELECT STDDEV(salary) FROM employees; |
| STDDEV_POP() | 返回人口标准差 | - |
| STDDEV_SAMP() | 返回样本标准差 | - |
| VAR_POP() | 返回人口方差 | - |
| VAR_SAMP() | 返回样本方差 | - |
| VARIANCE() | 返回方差(等同于 VAR_POP()) | - |
| JSON_ARRAYAGG() | 将结果集聚合为 JSON 数组 | SELECT JSON_ARRAYAGG(name) FROM employees; |
| JSON_OBJECTAGG() | 将键值对聚合为 JSON 对象 | SELECT JSON_OBJECTAGG(key, value) FROM table; |
注意事项
- 大多数聚合函数忽略 NULL 值(COUNT(*) 除外)。
- 常用场景下,最核心的五个是:COUNT()、SUM()、AVG()、MAX()、MIN()。
- GROUP_CONCAT() 是 MySQL 特有的,非常实用,用于将分组数据拼接成字符串。
- 在 SELECT 中使用聚合函数时,如果有 GROUP BY,则 SELECT 列表中非聚合的列必须出现在 GROUP BY 中。
- 过滤分组结果使用 HAVING 子句(而非 WHERE),因为 HAVING 在分组后执行。
mysql 原理
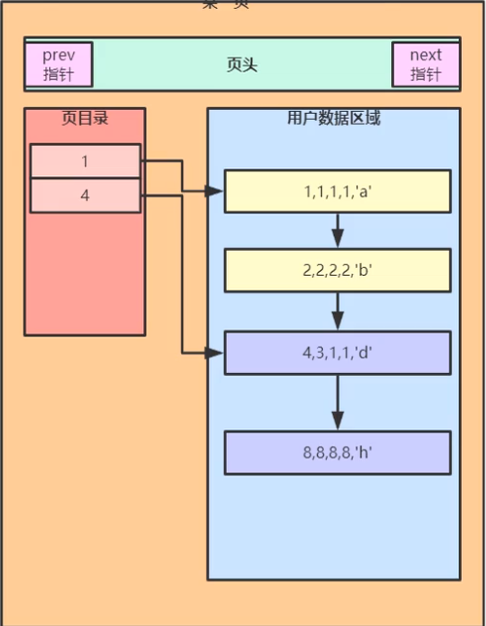
mysql 是 B+树。存储的页 链表(长链表)形式 根据存储的主键排序 加上页目录(索引)4 可以做到根据索引来查询时 效率变快 页是数组实现的,可以根据数据预估页大小 会根据二分查找法来定位页在哪 同理页码也可以存起来在一个数组中,利用二分定位法可以很快的定位 目录页在可以更快的查询数据 形成了 B+树 也就是索引
二分查找法:找寻值存在哪两个值之间(取一半数据比较没有再取一半这样)
B+树
- 三大特点
- 叶子节点之间有指针指向
- 非叶子节点的数据都冗余在叶子节点中
- 一个节点中可以存多个元素
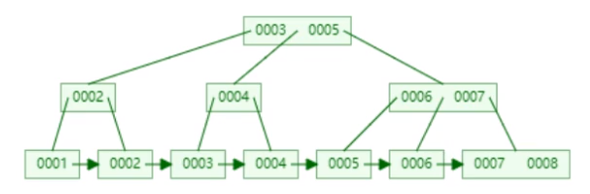
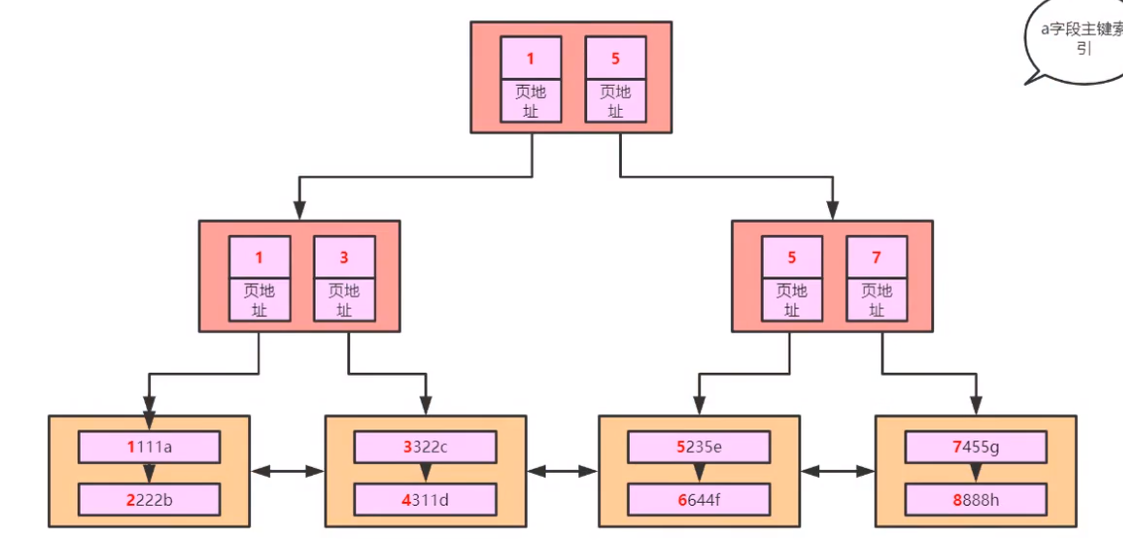
从上到下就是索引,从左到右就是全表扫描
每个索引都对应一个 B+树
去重使用distinct还是group by
- 简单去重 使用distinct
- 数据量巨大时,不要使用聚合函数
索引
索引就是数据结构
字符与数字比较时。字符会转成数字 所以 当索引字段有运算时,索引都不会生效
索引分类:
CREATE INDEX index_mytable_name ON tablename(name);ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY [索引名] (字段名1 [(长度)] )ALTER TABLE table_name ADD INDEX index_name ON (column(length))- 普通索引:查询加速,无限制
- 唯一索引:具有唯一性 UNIQUE
- 主键索引:
- 组合索引:多个字段上创建的索引,当查询条件使用了索引的第一个字段才生效
- 前缀索引:截取长度索引,如有重复的 可以提升查询效率
- 全文索引:查询关键字 FULLTEXT
- 1.命名规则 唯一性索引用uni_开头,后面跟表名。一般性索引用ind_开头,后面跟表名。
强制使用索引 select * from table force index(PRI) limit 2;??
显示一个表里的所有索引 show index from 表名
查询原理
- 查询的 2 种方式
- 索引 (B+树 从上到下)
- 全表扫描(B+树 从左到右)
什么是回表 在联合索引时只会存储联合索引的字段数据和主键,如果你根据联合索引的字段来查询全表字段 他会根据查询到的数据的主键,再去主键的 B+树中查询所有数据,这就叫回表
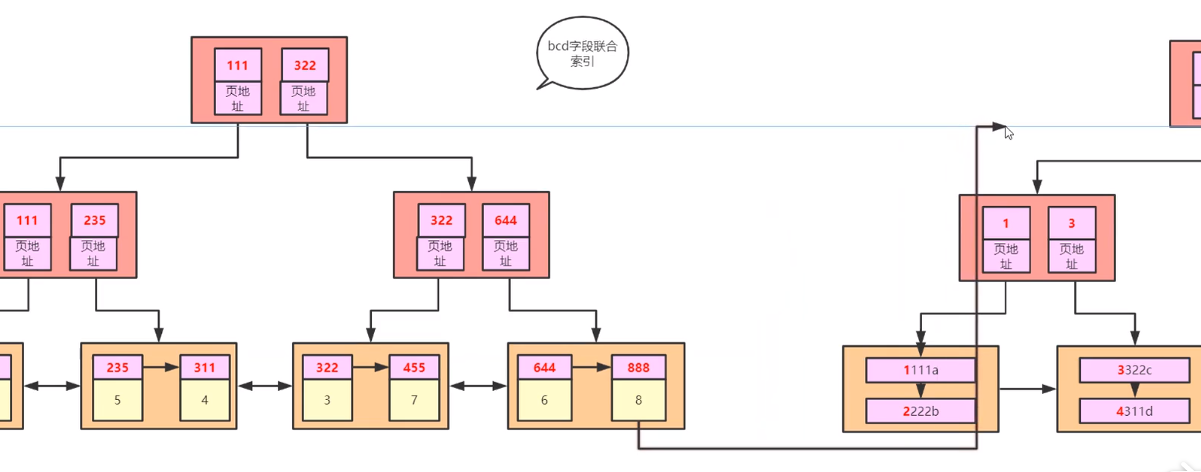
- 最左前缀原则
在联合索引时 如果没有给索引的第一个字段时 无法使用索引,因为无法用第一个字段比较定位。所以联合索引要想生效 最少需要最左边的一个字段
- 索引条件向推
联合索引中 没有使用中间字段当做条件时 会根据前缀查询之后再去过滤另一个字段 在进行回表。
视图:
作用:
权限控制时使用
简单复杂的查询
大表分表查询,合成查询
视图from后不能用子查询
修改视图影响基表,修改基表影响视图
视图如果from自表 则可以更新修改删除
创建:create view sales_view as select ..... 查看:show create view 视图名
触发器
创建: create TRIGGER 触发器名 [before|after [insert|udate|delete] on 表名 for each row begin ... end;
row 每行受影响,触发器都执行,叫行级触发器。
触发器的 old 和 new after 触发器—是在记录操纵之后触发,是先完成数据的增删改,再触发,触发的语句晚于监视的增删改操作,无法影响前面的增删改动作 before 触发器—是在记录操纵之前触发,是先完成触发,再增删改,触发的语句先于监视的增删改,我们就有机会判断,修改即将发生的操作,如:我们在触发之前需要判断 new 值和 old 值的大小或关系,如果满足要求就触发,不通过就修改再触发;如:表之间定义的有外键,在删除主键时,必须要先删除外键表,这时就有先后之分,这里 before 相当于设置了断点,我们可以处理删除外键。
- 对于 INSERT 语句, 只有 NEW 是合法的;
- 对于 DELETE 语句,只有 OLD 才合法;
- 对于 UPDATE 语句,NEW、OLD 可以同时使用。
INSERT INTO x_test(x_name,x_time) SELECT CONCAT(rand()*3300102,x_name),x_time FROM x_test WHERE id < 30000;
外键
- CASCADE:父表delete、update的时候,子表会delete、update掉关联记录;
- SET NULL:父表delete、update的时候,子表会将关联记录的外键字段所在列设为null,所以注意在设计子表时外键不能设为not null;
- RESTRICT:如果想要删除父表的记录时,而在子表中有关联该父表的记录,则不允许删除父表中的记录;
- NO ACTION:同 RESTRICT,也是首先先检查外键;
- 解除外键约束 SET FOREIGN_KEY_CHECKS=0; 重启SET FOREIGN_KEY_CHECKS=1;
- alter table book drop foreign key fk_book_cid;
- alter table book add constraint fk_book_cid foreign key(cid) references category(cid);
导出错误 1290 my.ini 在[mysqld]内加入 secure_file_priv =
mysql 监控日志
# 查看日志是否开启
show variables like "general_log%";
# 开启日志
set global general_log='ON'
# 之后查看日志优化
- 常见影响因素
- 1.数据库结构设计
- 了解业务
- 第三范式设计
- 表关联少
- 最小原则
- 1.数据库结构设计
面试题 是否全表扫描
CREATE TABLE `t_collect` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`cid` int(11) DEFAULT NULL COMMENT '内容 id',
`type` int(11) DEFAULT NULL COMMENT '类型 0:蜂品种;1:蜂产品;2:病虫害',
`state` int(11) DEFAULT NULL COMMENT '状态 0:取消;1:收藏',
`uid` int(11) DEFAULT NULL COMMENT '收藏人 id',
`modifyTime` datetime DEFAULT NULL COMMENT '修改时间',
`createTime` datetime DEFAULT NULL COMMENT '收藏时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='收藏表';
ALTER TABLE `t_collect` ADD INDEX cid_type (cid,type);
explain select _ from t_collect where cid = 1
explain select _ from t_collect where type = 1
explain select _ from t_collect where type = 1 and cid = 1
explain select _ from t_collect where cid = 1 and type = 1
- system: 表中只有一条数据. 这个类型是特殊的 const 类型.
- const: 针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可
- eq_ref: 此类型通常出现在多表的 join 查询, 表示对于前表的每一个结果, 都只能匹配到后表的一行结果. 并且查询的比较操作通常是 =, 查询效率较高. 关键字:连接字段 主键或者唯一性索引
- ref : 此类型通常出现在多表的 join 查询, 针对于非唯一或非主键索引, 或者是使用了 最左前缀 规则索引的查询. 关键字:非唯一性索引
- ref_or_null:与 ref 方法类似,只是增加了 null 值的比较。
- range: 表示使用索引范围查询, 通过索引字段范围获取表中部分数据记录. 这个类型通常出现在 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, IN() 操作中.
- index: 表示全索引扫描(full index scan), 关键字:查询字段和条件都是索引本身
- index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见 and ,or 的条件使用了不同的索引.效率不是很高 关键字:索引合并
- unique_subquery:用于 where 中的 in 形式子查询,子查询返回不重复值唯一值
- index_subquery:用于 in 形式子查询使用到了辅助索引或者 in 常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
- fulltext:全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql 不管代价,优先选择使用全文索引
- all:这个就是全表扫描数据文件,然后再在 server 层进行过滤返回符合要求的记录。三 效率总结
- 1 依次从好到差:
- system,const,index , range,index_merge,ALL 单独查询
- eq_ref,ref,ref_or_null all 多表join 查询
- index_subquery unique_subquery 子查询
- 2 index_merge 之外,其他的 type 只可以用到一个索引