
外观
深入模型训练 Pytorch
由 MNN 衍生发现想要运行MNN模型还是需要从依赖Pytorch/TF来训练。
总结MNN流程:准备PyTorch模型 -> 使用 llmexport.py 导出为 MNN 格式 -> 编译 MNN 引擎 (启用 LLM) -> 配置 config.json -> 使用 llm_demo 进行推理
Pytorch 与 TF
都是目前深度学习领域的主流框架
Pytorch
pytorch 是基于 Python 构建的深度学习框架,意思是他是python的一个扩展库。
pytorch 的核心底层是用 c++/CUDA 实现的
上层是python api(torch模块)面对开发者,好调试。 底层是 C++/CUDA (张量库、自动求导引擎)为核心是实现的高性能跨平台
核心概念:
张量(Tensor)操作
自动求导(autograd)
构建模型(nn.Module)
数据加载(DataLoader + Dataset)
训练循环(前向传播、损失计算、反向传播、参数更新)
常规用法
常规用法是在python中用pytorch训练,调试模型;然后将训练好的模型导出,使用c++加载并推理;
当你够熟悉或者需要极致性能,可以直接用c++开发pytorch模型,无需python参与。
步骤:
- python端训练导出模型
import torch
import torch.nn as nn
# 1. 定义一个简单的线性回归模型(
class LinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1) # 输入1维,输出1维
def forward(self, x):
return self.linear(x)
# 2. 训练模型(简化版,仅演示导出)
model = LinearModel()
# 模拟训练(实际项目中需完整训练)
x = torch.tensor([[1.0], [2.0], [3.0]])
y = model(x)
# 3. 导出为 TorchScript 格式(关键:桥接 Python 和 C++)
# 方式1:追踪式(适合无动态控制流的模型)
traced_model = torch.jit.trace(model, x)
# 方式2:脚本式(适合有if/for等动态逻辑的模型)
# scripted_model = torch.jit.script(model)
# 保存模型文件
traced_model.save("linear_model.pt")
print("模型已导出为 linear_model.pt")- C++端加载运行模型
// 先安装LibTorch库 pytorch的c++库: https://pytorch.org/get-started/locally/
#include <torch/torch.h>
#include <iostream>
int main() {
// 1. 加载 TorchScript 模型
std::string model_path = "linear_model.pt";
torch::jit::script::Module model;
try {
model = torch::jit::load(model_path);
std::cout << "模型加载成功!" << std::endl;
} catch (const c10::Error& e) {
std::cerr << "加载模型失败:" << e.what() << std::endl;
return -1;
}
// 2. 准备输入数据(C++ 张量,和 Python 张量对应)
// 创建 [1,1] 的张量,值为 5.0(对应 Python 的 torch.tensor([[5.0]]))
torch::Tensor input = torch::tensor({{5.0}}, torch::kFloat32);
// 3. 构造输入列表(PyTorch C++ 要求输入封装为 vector)
std::vector<torch::jit::IValue> inputs;
inputs.push_back(input);
// 4. 执行推理(前向传播)
torch::Tensor output = model.forward(inputs).toTensor();
// 5. 输出结果
std::cout << "输入:5.0,预测结果:" << output.item<float>() << std::endl;
return 0;
}TensorFlow
TensorFlow有google开发的,核心优势是工业级的部署能力和完整的生态系统; 他也是由c++实现,上层使用python等语言
Code!
手写线性回归
线性回归(Linear Regression):
- 线性:直线(单调的均匀变化的)
- 回归:往回推,找规律。把杂乱的数据回归到他本来的趋势线上。
最简单的监督学习任务,本质上就是用数据拟合出一条线,预测未来的结果。
比如带入场景
- 学习时间 vs 考试成绩:一般来说,学的越久(X),分越高(Y)。线性回归就是找出多学 1 小时,大概能提多少分。
- 广告费 vs 销售额:投的钱越多(X),卖得越多(Y)。线性回归就是算出每投 1 万广告费,大概能带来多少销售额。
- 在线性回归的基础上深入一下 -> 逻辑回归可以做分类任务
掌握框架的核心流程:数据准备 → 模型定义 → 损失函数 / 优化器 → 训练循环 → 验证。
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 1.生成数据集 (拿房子价格来举例)
x = torch.randn(200,1) # 生成100个样本,每个样本有1个特征 (选取100套房子的面积数)
y = 2 * x + 3 + 0.3 * torch.randn(200,1) # 基于x生成y,规律是y=2x+3, 真实数据没这么规律加少量噪声(房子的价格变化)
# 2.定义模型 单层线性层
model = nn.Linear(1,1) #一个输入特征数(房子面积),一个输出特征数 (预测价格)
# 3.定义损失函数和优化器
#均方误差,预测值与真实值的差的平方的平均值; 数值越小说明预测越准
criterion = nn.MSELoss()
#优化器,负责调整模型的参数,让他越学越准
#SGD:随机梯度下降,最基础的优化算法
#lr=0.01 学习率:相当于迈的步子大小, 太大可能跨过头找不到最佳点 太小会学得慢 需要时间长
optimizer = torch.optim.SGD(model.parameters(),lr=0.02) #随机梯度下降,学习率0.1
# 4.循环训练
epochs = 200
loss_history = []
for epoch in range(epochs):
y_pred = model(x) #应用当前模型来预测 前向传播 预测y
#计算损失
loss = criterion(y_pred,y) #计算预测得准不准 *随便找个数
loss_history.append(loss.item()) #记录损失值 损失的越多说明越不准!*看看跟本来的值差了多少
#反向传播+优化
optimizer.zero_grad() #梯度清零 *忘掉上一个值
loss.backward() #反向传播计算梯度 *分析原因,看看预测的值多了还是少了
optimizer.step() #更新模型参数 *根据分析的结果调整一下预测方式
#每10轮打印一次损失
if(epoch+1) %10==0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}")
# 5.验证模型
print("\n训练后的模型参数:") #打印训练后的参数 理想值w≈2 b≈3
for name,param in model.named_parameters():
print(f"{name}: {param.data.item():.4f}")
#可视化结果
plt.figure(figsize=(10,4))
#子图1:损失变化 *看模型是不是越学越好(曲线应该下降)
plt.subplot(1,2,1)
plt.plot(loss_history)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.title("Training Loss")
#子图2 真实值与预测值 *红线和蓝点越贴近,说明学得越好
plt.subplot(1,2,2)
plt.scatter(x.numpy(),y.numpy(),label="True Data")
plt.plot(x.numpy(),model(x).detach().numpy() ,color='red',label="Prediction")
plt.legend()
plt.title("True and prediction")
plt.show()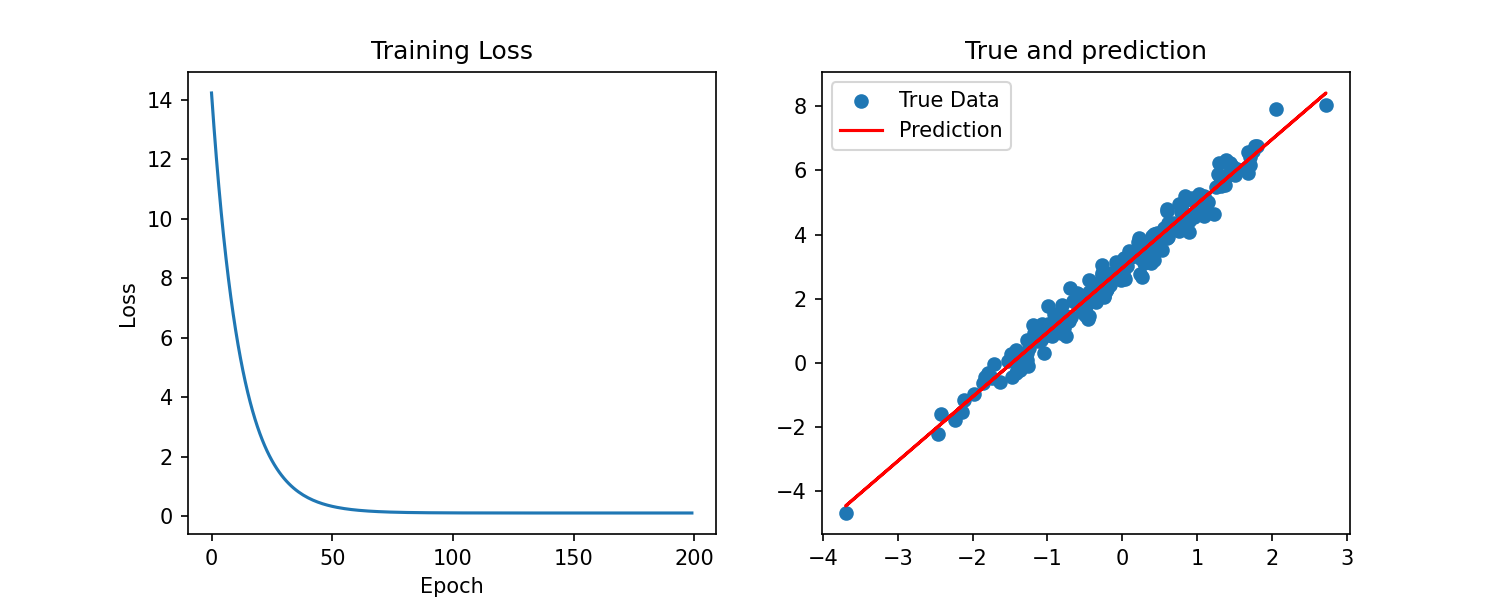
总结:
x是特征张量(模型的输入),y是标签张量(y)。二者一一对应,形状为:[样本数,特征/标签维度]- x和y是随机生成的模型数据,满足y=2x+3+噪声,目的是为了让模型学习找个线性关系
- 真实场景中,x与y需要从文件中加载并转化成框架支持的张量格式,核心逻辑(特征 - 标签对应)。
深度学习的Hello World! 手写数字识别(MNIST 数据集)
MNIST:Modified National Institute of Standards and Technology(修改后的国家标准与技术研究所),一个包含了大量手写数字图片的数据集。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
#训练参数
batch_size = 64 #批次大小 *每次训练多少张图, 太大可能显存/内存不够,太小训练慢。 批次太小→训练慢且不稳定,批次太大→显存不够且泛化能力差
learning_rate = 0.02 #学习率
epochs = 5 #训练轮数
# 1.加载数据集 自动下载
transform = transforms.ToTensor()
train_dataset = datasets.MNIST(root="./data",train=True,transform=transform,download=True)
test_dataset = datasets.MNIST(root="./data",train=False,transform=transform)
train_loader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(test_dataset,batch_size=batch_size,shuffle=False)
# 2.定义模型
#全连接模型
class SimpleMLP(nn.Module):
def __init__(self):
super(SimpleMLP,self).__init__()
self.model = nn.Sequential(
nn.Flatten(), #将28x28的图像展平为784维的向量
nn.Linear(784,128), #线性层,输入784维,输出128维
nn.ReLU(),
nn.Linear(128,10) #线性层,输入128维,输出10维(对应10个数字类别)
)
def forward(self,x):
return self.model(x)
#CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN,self).__init__()
#卷积层1,输入1通道(灰度图一个通道),输出16通道(提取16个不同的特征器(卷积核)),卷积核大小3x3(3*3的窗口扫描图片,提取特征),步长1(卷积核每次向右/下移动1个像素。步长越大输出尺寸越小),填充1保持尺寸不变(在图片边缘补一圈0 保证尺寸)
self.conv1 = nn.Conv2d(1,16,kernel_size=3,stride=1,padding=1) #CNN的核心层,作用是提取图像的局部特征(比如数字的边缘,线条,拐角)
self.relu=nn.ReLU() #激活函数 引入非线性,能拟合更复杂的特征; ReLU:`y = max(0, x)`只保留正数,把负数置 0 → 相当于 “筛选有用特征,丢弃无用特征”;
#池化层,尺寸减半(窗口大小2x2) MaxPool2d(2)表示使用2x2的窗口进行最大池化,即每4个像素取最大值,输出尺寸减半。
self.pool = nn.MaxPool2d(2) #池化层的作用是降维(降低特征图的尺寸,减少参数数量和计算量,同时保留重要特征)。28×28 的特征图 → 池化后变成 14×14(尺寸减半,计算量减少 75%); 比如数字 “8” 的轮廓,池化后依然能保留 “两个圈” 的核心特征,但像素点更少了
#第二个卷积层,输入16通道(上一层输出的特征图数量),输出32通道(提取32个不同的特征),卷积核大小3x3,步长1,填充1保持尺寸不变。池化后尺寸变成7x7,特征图数量变成32,所以全连接层输入维度是32*7*7=1568
self.conv2 = nn.Conv2d(16,32,kernel_size=3,stride=1,padding=1) #提取更父杂的特征,比如数字的整体形状,笔画的连接方式等。第一层提取的是局部特征,第二层提取的是更抽象的全局特征。
#全连接层1,输入1568 维(卷积 2 池化后的特征图尺寸是 32通道 × 7×7像素 → 展平后是 32×7×7=1568 维向量),输出128维
self.fc1 = nn.Linear(32*7*7,128) #把卷积提取的特征映射到高维特征空间,为最终分类做准备
#全连接层2,输入128维(对应 fc1 的输出维度(必须匹配)),输出10维(对应10个数字类别 0-9的分类)
self.fc2 = nn.Linear(128,10) #最终分类,把 128 维特征映射到 10 个类别(0-9)。
#前向传播:输入图像经过卷积层1、激活函数、池化层,卷积层2、激活函数、展平为向量,经过全连接层1、激活函数、全连接层2得到输出
def forward(self,x):
# 前向传播是数据在各个层里(网络)中的 “流动路径”
#卷积层1 + 激活函数 + 池化层
x=self.pool(self.relu(self.conv1(x))) #流动路径及维度变化:输入图像(64张图、1通道、28×28) → conv1 卷积层1提取局部特征((64, 16, 28, 28)通道变16,尺寸不变)) → ReLU激活函数((64, 16, 28, 28)只是数值变化) → pool 池化层降维保留重要特征(64, 16, 14, 14)尺寸减半)
#卷积层2 + 激活;卷积层2提取更复杂的特征
x=self.pool(self.relu(self.conv2(x))) #流动路径及维度变化:接收第一步的结果维度(64, 16, 14, 14) → conv2 卷积层2((64, 32, 14, 14)通道变32,尺寸不变) → ReLU激活函数(64, 32, 14, 14) → pool 池化层降维保留重要特征(64, 32, 7, 7)尺寸减半)
#展平为向量,-1表示自动计算批次大小
x=x.view(-1,32*7*7) # x = x.flatten(1) 将二维的特征图转成一维向量,输入全连接层。 流动路径及维度变化:接收第二步的结果维度(64, 32, 7, 7) → 展平为向量(64, 1568) 32*7*7=1568 (64 个样本,每个样本 1568 维)
#全连接层1 + 激活函数
x=self.relu(self.fc1(x)) # 接上一步输入维度(64,1568) → fc1 全连接层1(64,128) → ReLU激活函数(64,128)
#全连接层2
x=self.fc2(x) #接上一步输入维度(64,128) → fc2 全连接层2(64,10) 输出10维对应10个类别的得分(logits),后续会通过损失函数计算概率并进行分类决策。
return x
# 实例模型 全连接
# model = SimpleMLP().to(device)
# 实例模型 CNN
model = SimpleCNN().to(device)
#定义损失函数和优化器
criterion = nn.CrossEntropyLoss() #交叉熵损失函数,适用于多分类问题
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate) #Adam优化器,学习率0.001
# 训练模型
def train_model(model, train_loader, criterion, optimizer, epoch):
model.train() #设置模型为训练模式
train_loss = 0.0
for batch_x,(data,target) in enumerate(train_loader):
data,target = data.to(device),target.to(device) #将数据移到GPU
optimizer.zero_grad() #清零梯度
outputs = model(data) #前向传播
loss = criterion(outputs,target) #计算损失
loss.backward() #反向传播
optimizer.step() #更新参数
train_loss += loss.item()
if(batch_x+1) % 100 == 0: #每100个批次打印一次损失
print(f"Epoch [{epoch+1}/{epochs}], Step [{batch_x+1}/{len(train_loader)}], Loss: {loss.item():.4f}")
train_loss = 0.0 #重置损失值
def test(model, test_loader, criterion):
model.eval() #设置模型为评估模式
correct, total = 0,0
with torch.no_grad(): #评估时不计算梯度
for data,target in test_loader:
data,target = data.to(device),target.to(device)
outputs = model(data)
test_loss = criterion(outputs,target).item() #计算测试损失
pred = outputs.argmax(dim=1,keepdim=True) #取最大值的索引作为预测类别
correct += pred.eq(target.view_as(pred)).sum().item() #统计正确预测的数量
total += target.size(0) #统计总的测试样本数量
test_loss /= len(test_loader.dataset) #计算平均损失
accuracy = 100 * correct / len(test_loader.dataset) #计算准确率,正确预测的数量除以总的测试样本数量
print(f'\nTest set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')
return accuracy
if __name__ == "__main1__":
best_accuracy = 0.0
for epoch in range(epochs):
train_model(model,train_loader,criterion,optimizer,epoch)
curent_accuracy = test(model,test_loader,criterion)
if curent_accuracy> best_accuracy:
best_accuracy = curent_accuracy
torch.save(model.state_dict(),'mnist_best_model.pth') #保存最优模型参数
print(f'训练完成!最高测试准确率:{best_accuracy:.2f}%')
#============================== 训练结束 ===========================================
#=== MLP训练完成!最高测试准确率:95.39% ========
#=== CNN训练完成!最高测试准确率:97.15% ========
# ========================== 验证推理: 可视化预测结果 ===========================
def visualize_predictions():
# 加载最优模型
model.load_state_dict(torch.load('mnist_best_model.pth'))
model.eval()
# 取测试集前5张图片
#关于推理的图片,由于训练使用的是28*28的灰度图,像素值0-1,背景黑/数字白的MNIST格式,所以如果随便上传图片进行推理,会有问题。
#也需要转换成28*28的灰度图,像素值0-1,背景黑/数字白的MNIST格式,才能得到正确的预测结果。
data_iter = iter(test_loader)
images, labels = next(data_iter)
images, labels = images.to(device), labels.to(device)
# 预测
outputs = model(images)
preds = outputs.argmax(dim=1)
# 可视化
plt.figure(figsize=(10, 4))
for i in range(11):
plt.subplot(1, 11, i+1)
# 转成CPU+numpy,恢复原始尺寸(去掉通道维度)
img = images[i].cpu().squeeze().numpy()
plt.imshow(img, cmap='gray')
plt.title(f'Pred: {preds[i].item()}\nTrue: {labels[i].item()}')
plt.axis('off')
plt.tight_layout()
plt.show()
# 运行可视化
visualize_predictions()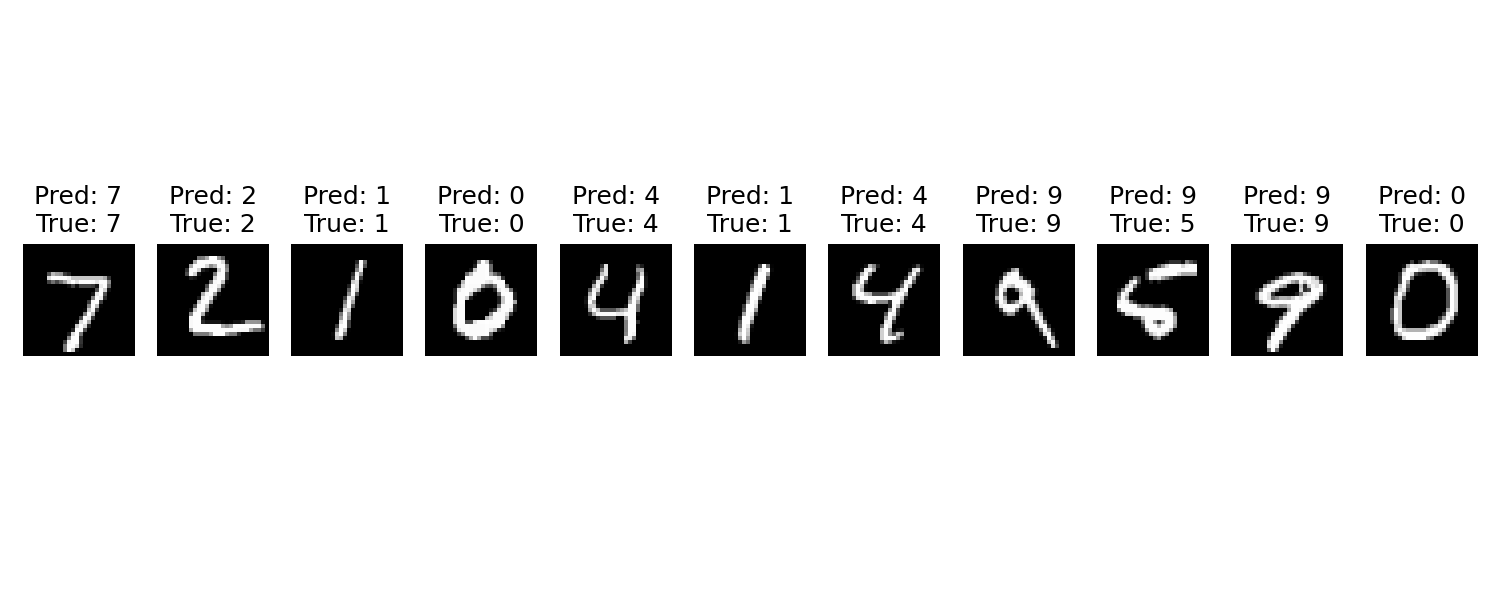
CNN层的概念
层 = 流水线工位
| 层类型 | 核心作用 | 维度变化(MNIST 示例) |
|---|---|---|
| 卷积层(Conv2d) | 提取局部特征 | 通道数增加,尺寸不变(靠 padding) |
| 池化层(MaxPool2d) | 降维 + 保留关键特征 | 尺寸减半,通道数不变 |
| 全连接层(Linear) | 特征映射 + 分类 | 把高维特征转成类别得分 |
| 数据流动步骤 | 经过的 “层” | 输入维度 | 层的加工操作 | 输出维度 |
|---|---|---|---|---|
| 第一步 | 卷积层 1 | (64,1,28,28) | 提取 16 种局部特征 | (64,16,28,28) |
| 第二步 | ReLU 层 | (64,16,28,28) | 筛选有用特征(非线性) | (64,16,28,28) |
| 第三步 | 池化层 | (64,16,28,28) | 降维 + 保留关键特征 | (64,16,14,14) |
| 第四步 | 卷积层 2 | (64,16,14,14) | 提取 32 种更复杂特征 | (64,32,14,14) |
| 第五步 | ReLU 层 | (64,32,14,14) | 筛选有用特征 | (64,32,14,14) |
| 第六步 | 池化层 | (64,32,14,14) | 再次降维 | (64,32,7,7) |
| 第七步 | 展平层(view/flatten) | (64,32,7,7) | 转一维向量 | (64,1568) |
| 第八步 | 全连接层 1 | (64,1568) | 特征映射 | (64,128) |
| 第九步 | ReLU 层 | (64,128) | 非线性变换 | (64,128) |
| 第十步 | 全连接层 2 | (64,128) | 最终分类 | (64,10) |
- 每一层的输出维度,就是下一层的输入维度(必须严格匹配,否则会报维度错误);
- 前向传播的
forward函数,就是按这个顺序把层 “串起来” - 网络的复杂度,本质就是 “层的数量 + 每层的参数数量”(比如 CNN 比全连接网络多了卷积层 / 池化层,能处理图像的空间特征)。
总结
- 网络就是按特定顺序排列的层的集合,前向传播就是数据 “穿过每一层” 的过程;
- 每一层的输入维度必须和上一层的输出维度匹配(这是维度报错的核心原因);
__init__定义 “有哪些层”,forward定义 “层的执行顺序”—— 这是 PyTorch 模型的核心逻辑。
LLM
import torch
import torch.nn as nn
import torch.nn.functional as F
import os
# 1. 模型定义
class MiniLLM(nn.Module):
# 初始化模型,定义模型里有哪些层(词嵌入层、位置编码层、Transformer解码器层和输出层)
# 参数(词汇表大小、嵌入维度、注意力头数、最大序列长度)
def __init__(self, vocab_size, embed_dim, num_heads, max_seq_len):
super().__init__()
self.max_seq_len = max_seq_len
self.embed_dim = embed_dim
# 词嵌入层:把 单词ID → 向量
# 输入:词汇表大小,输出:词向量维度
self.token_embedding = nn.Embedding(vocab_size, embed_dim)
# 位置嵌入层:给模型“知道单词在句子里的位置”
# 因为 Transformer 不知道顺序,必须加位置信息
self.pos_embedding = nn.Embedding(max_seq_len, embed_dim)
# 定义一层 Transformer Decoder(语言模型核心)
decoder_layer = nn.TransformerDecoderLayer(
d_model=embed_dim, # 模型维度 = 词向量维度
nhead=num_heads, # 多头注意力数量
dim_feedforward=embed_dim*2, # 前馈网络维度(通常是2倍)
dropout=0.1, # 随机失活,防止过拟合
batch_first=True, # 输入形状优先:(批次, 序列长度, 维度)
activation='gelu' # 激活函数,比 relu 更平滑
)
# 把 N 层 Decoder 叠起来,这里用 2 层
self.transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=2)
# 全连接层:把模型输出 → 映射到词汇表,预测下一个词
self.fc = nn.Linear(embed_dim, vocab_size)
# 掩码(让模型只能看前面的词,不能偷看未来的词)
def generate_causal_mask(self, seq_len, device):
mask = torch.triu(torch.ones(seq_len, seq_len, device=device), diagonal=1)
mask = mask.masked_fill(mask == 1, float('-inf'))
return mask
# 前向传播:模型真正的计算过程
def forward(self, x):
# B = 批次大小(一次训练多少句话), S = 序列长度(一句话多少个字)
B, S = x.size()
# 把单词ID → 词向量
token_emb = self.token_embedding(x)
# 生成位置索引 [0,1,2,...S-1]
pos_idx = torch.arange(0, S, device=x.device).unsqueeze(0)
# 位置索引 → 位置向量
pos_emb = self.pos_embedding(pos_idx)
# 词向量 + 位置向量 = 最终输入向量
x = token_emb + pos_emb
tgt_mask = self.generate_causal_mask(S, x.device)
# 把向量送入 Transformer Decoder 计算
x = self.transformer_decoder(x, x, tgt_mask=tgt_mask)
# 全连接层输出 logits(未归一化的概率)
logits = self.fc(x)
return logits
# 2. 封装函数
def train_model(model, input_ids, target_ids, vocab_size, pad_id, epochs=100, lr=0.005, device='cpu'):
"""训练模型"""
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
loss_fn = nn.CrossEntropyLoss(ignore_index=pad_id)
model.train()
input_ids = input_ids.to(device)
target_ids = target_ids.to(device)
for epoch in range(epochs):
optimizer.zero_grad() # 清空上一步的梯度
logits = model(input_ids) # 把数据喂给模型,得到预测结果
# 计算损失:预测值 vs 真实值 .view(-1, vocab_size) 把形状展平,适配损失函数
loss = loss_fn(logits.view(-1, vocab_size), target_ids.view(-1))
# 反向传播:计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}")
return model
def save_model(model, path="./llm/llm_model.pt"):
"""保存模型"""
os.makedirs(os.path.dirname(path), exist_ok=True)
torch.save(model.state_dict(), path)
print(f"模型已保存:{path}")
def load_model(model_class, vocab_size, embed_dim, num_heads, max_seq_len, path="./llm/llm_model.pt", device='cpu'):
"""加载模型"""
# 创建一个空模型
model = model_class(vocab_size, embed_dim, num_heads, max_seq_len).to(device)
# 加载保存好的参数
model.load_state_dict(torch.load(path, map_location=device, weights_only=False))
model.eval()
print(f"模型已加载:{path}")
return model
def generate_text(model, start_tokens, idx2vocab, vocab, pad_id, max_new_tokens=10, temperature=1.0, device='cpu'):
"""生成文本(带温度采样)"""
model.eval()
generated = start_tokens.copy()
with torch.no_grad():
for _ in range(max_new_tokens):
current_seq = torch.tensor([generated], device=device)
logits = model(current_seq)
# 温度缩放
next_token_logits = logits[0, -1, :] / temperature
# 概率采样
probs = F.softmax(next_token_logits, dim=-1)
next_token_id = torch.multinomial(probs, num_samples=1).item()
# 防止越界
next_token_id = min(next_token_id, len(idx2vocab) - 1)
generated.append(next_token_id)
if next_token_id == vocab.get("<EOS>", 0):
break
return ''.join([idx2vocab.get(idx, "?") for idx in generated if idx != pad_id])
# 3. 配置 & 数据
vocab = {
"我":0, "今":1, "天":2, "很":3, "开":4, "心":5,
"你":6, "好":7, "爱":8, "他":9, "去":10, "学":11,
"校":12, "吃":13, "饭":14, "快":15, "乐":16,
"<PAD>":17, "<EOS>":18
}
idx2vocab = {idx: word for word, idx in vocab.items()}
vocab_size = len(vocab)
pad_id = vocab["<PAD>"] # 填充符号 ID(句子长度不够时用来补齐)
embed_dim = 16
num_heads = 2
max_seq_len = 10
# 训练数据:(输入句子, 目标句子)
training_data = [
([0, 1, 2, 3, 4, 5], [1, 2, 3, 4, 5, 18]), # 我今天很开心 → 今天很开心<EOS>
([0, 8, 6, 7], [8, 6, 7, 18]), # 我爱你好 → 爱你好<EOS>
([9, 10, 11, 12], [10, 11, 12, 18]), # 他去学校 → 去学校<EOS>
([0, 13, 14], [13, 14, 18]), # 我吃饭 → 吃饭<EOS>
([0, 3, 15, 16], [3, 15, 16, 18]), # 我很快乐 → 很快乐<EOS>
([6, 3, 4, 5], [3, 4, 5, 18]), # 你很开心 → 很开心<EOS>
]
# 把所有输入句子补齐到最大长度,不足补 <PAD>
input_ids = torch.tensor([s[0] + [pad_id]*(max_seq_len-len(s[0])) for s in training_data])
# 把所有目标句子补齐到最大长度,不足补 <PAD>
target_ids = torch.tensor([s[1] + [pad_id]*(max_seq_len-len(s[1])) for s in training_data])
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"device: {device}\n")
# 4. 调用
if __name__ == "__main__":
# # 训练
# print("==== 开始训练 ====")
# model = MiniLLM(vocab_size, embed_dim, num_heads, max_seq_len).to(device)
# model = train_model(model, input_ids, target_ids, vocab_size, pad_id, epochs=200, lr=0.005, device=device)
# print("==== 训练完成 ====\n")
# # 保存
# save_model(model, "./llm/llm_model.pt")
# 加载
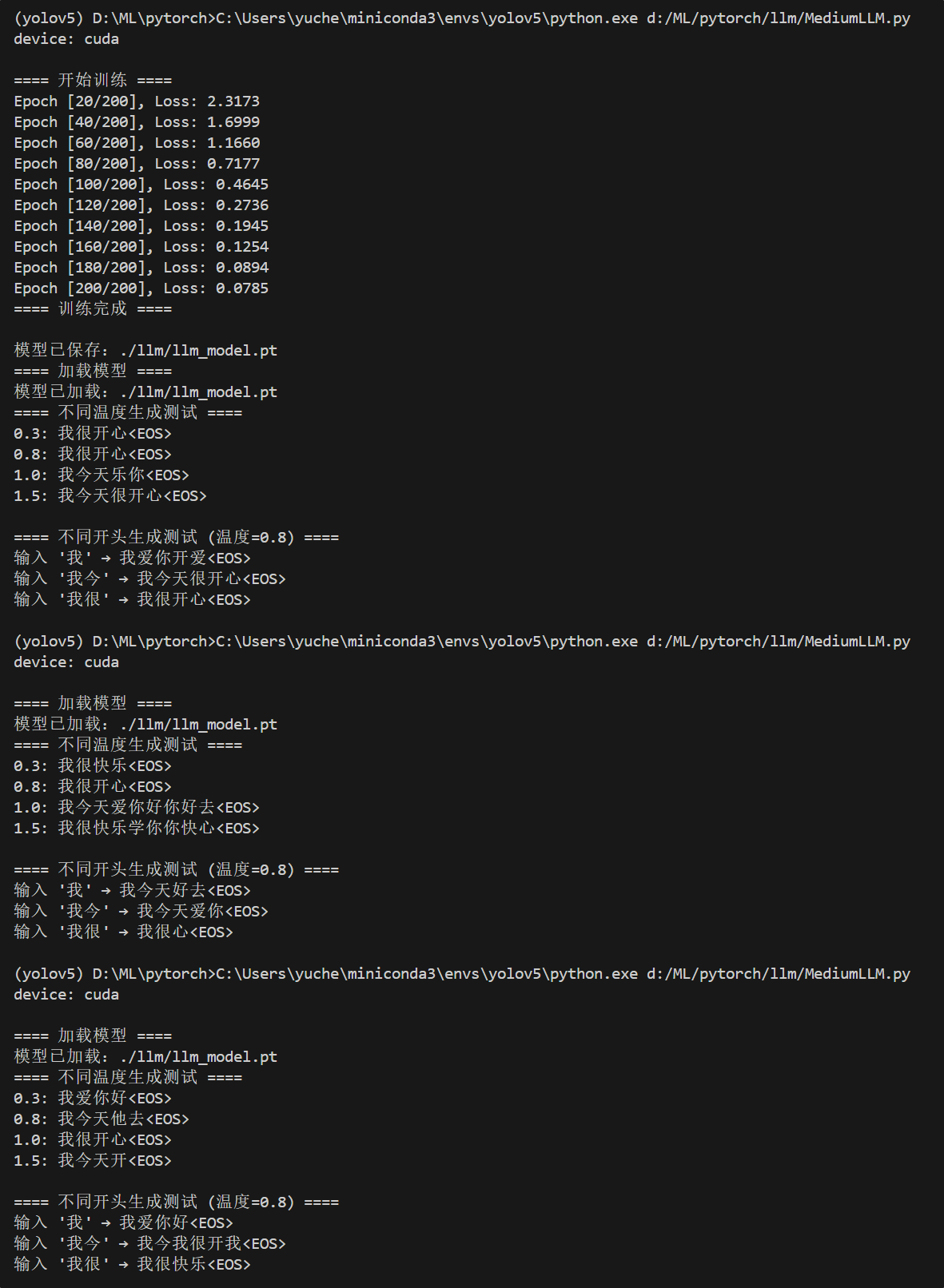
print("==== 加载模型 ====")
model = load_model(MiniLLM, vocab_size, embed_dim, num_heads, max_seq_len, "./llm/llm_model.pt", device)
# 生成测试:不同温度
print("==== 不同温度生成测试 ====")
for temp in [0.3, 0.8, 1.0, 1.5]:
result = generate_text(model, [0], idx2vocab, vocab, pad_id, max_new_tokens=10, temperature=temp, device=device)
print(f"{temp}: {result}")
# 不同开头测试
print("\n==== 不同开头生成测试 (T=0.8) ====")
for start in [[0], [0,1], [0,3]]:
start_words = ''.join([idx2vocab[i] for i in start])
result = generate_text(model, start, idx2vocab, vocab, pad_id, max_new_tokens=10, temperature=0.8, device=device)
print(f"输入 '{start_words}' → {result}")流程:(词嵌入)词嵌入:把汉字变成数字向量 -> (位置嵌入)告诉模型字的顺序 -> (Transformer Decoder)靠 “注意力” 看前面的字,预测下一个字 -> (全连接层)输出概率,选概率最大的字
通俗点:把汉字变成数字向量 -> 喂给模型训练 - > 模型学会了汉字之间的关系 - > 给一个开头,模型能预测下一个字 - > 不断循环,生成一段文本
总结
这就是一个模型微型版的预训练过程
预训练
预训练 = 让模型不停做“猜下一个字”的游戏,猜错了就改,猜对了就记住规律。
- ([0,1,2,3,4,5], [1,2,3,4,5,18]) => 我今天很开心 → 今天很开心<EOS>
- 模型看到:
我 → 今 → 天 → 很 → 开,必须预测下一个字是:心- 模型预测错 → 反向传播改参数
- 模型预测对 → 强化这个规律
- 模型看到:
- 模型不是死记硬背句子,是在学习语言规律、语法、搭配、逻辑
- 学习之后理解规律语法之类的,就能输出你没喂过她的句子
实际的大模型训练 数据量超大(万亿级别),模型超大 层数过百,训练时间也长。