
外观
Yolo
YOLO是一种实时目标检测算法,它的核心思想是在单次前向传播中同时预测图像中的多个目标的位置和类别。YOLO将输入图像划分为多个网格,每个网格负责预测中心点落在该网格内的目标。YOLO通过CNN提取特征,并将目标检测任务转化为回归问题,从而在保持较高检测精度的同时实现快速的检测速度。
显卡基础:
- 架构:相当于运行布局,布局越好跑的越流畅。
- 工艺:制程越小精度越高,越能发挥更多性能。
- 光栅以及流处理器:相当于劳动力,人越多执行力越强。
- 核心频率:反应速度,相当于跑车百米提速效率。
- 显存频率:相当于限速标志,决定了最大运行速度。
- 显存位宽:相当于划线,决定了最大运行通道。
- 显存容量:相当于道路限宽,决定了最大承载量。
基础环境与包
电脑环境:NVIDIA-SMI 536.99 Driver Version: 536.99 CUDA Version: 12.2
cuda 显卡驱动支持
- 先查看 cuda 版本
nvidia-smi,没有则下载对于版本的工具CUDA Toolkit Archive | NVIDIA Developer
Anconda - conda 安装
Conda 是一个流行的跨平台包管理器,可以用来安装运行更新包和他们的依赖项。下载地址 conda看作一个虚拟机,里面可以下载配置各种环境,下载使用指定版本的python等
配置方式 (已验证)
YOLOv5 项目:环境配置_yolo v5 环境-CSDN 博客
#基础环境安装
conda create -n yolo python=3.8
conda activate yolo
conda env list
conda deactivate #销毁虚拟环境
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
#torch安装
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
#下载yolov5
git clone --depth=1 --branch=master --single-branch https://github.com/ultralytics/yolov5.git
#安装
#安装时注意,requirments中的包不要覆盖手动装的torch,否则启用不了GPU
pip install -r requirements.txt*注意torch的版本对应cuda下载的时候注意 否则很容易bug溢出等 Start Locally | PyTorch
## 运行
```python
#查看对应的版本,是否使用到了GPU
import torch
print(torch.cuda.is_available())
print("torch V:"+torch.__version__)
True
0.20.1+cu124
# 如果输出false,一般是torch版本问题
# 卸载之后重装再尝试
pip uninstall torch torchvision torchaudio
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124数据标注
使用 labelimg
- 安装:
pip install labelimg, 使用:labelimg
模型检测【detect】
python train.py --weights ./models/yolov5m.pt --data ./data/locate.yaml --imgsz 1280 --batch-size 6
检测参数
模型路径:
*`--weights` 参数允许你指定模型权重文件的路径,可以是单个文件或多个文件列表 。
数据源:
*`--source` 参数定义了输入数据的来源,可以是图片、视频文件路径,或者使用摄像头 (`0`) 作为输入 。
数据集配置:
*`--data` 参数提供了数据集的配置文件路径,该文件包含了类别信息和图片路径等 。
图像尺寸:
*`--imgsz` 或 `--img` 或 `--img-size` 参数定义了输入图像的尺寸,通常用于指定网络输入的高和宽 。
置信度阈值
`--conf-thres` 参数设置了检测对象的置信度阈值,默认为 0.25 。
NMS IoU 阈值
`--iou-thres` 参数用于非极大值抑制(NMS)的 IoU 阈值,默认为 0.45 。
最大检测数:
`--max-det` 参数定义了每张图片中最多检测到的对象数量,默认为 1000 。
设备选择:
`--device` 参数允许你选择执行设备,如 CPU 或 CUDA 设备(例如 `0`, `0,1,2,3` 或 `cpu`)。
结果可视化:
`--view-img` 参数在设置为 `True` 时会在电脑界面显示检测结果 。
保存结果:
`--save-txt` 参数将检测结果保存到文本文件中
`--save-conf` 将置信度一并保存
`--save-crop` 保存裁剪的预测框图片,而 `--nosave` 则不保存任何图片或视频 。
类别过滤:
`--classes` 参数允许你通过指定类别索引来过滤检测结果 。
NMS 类别无关性
`--agnostic-nms` 参数用于执行与类别无关的 NMS 。
增强推理
`--augment` 参数在测试时进行增强推理,可能会提高模型性能 。
特征可视化:
`--visualize` 参数用于可视化网络层的输出特征 。
模型更新:
`--update` 参数用于更新所有模型,去除 `pt` 文件中的优化器等信息 。
结果保存路径
`--project` 和 `--name` 参数定义了保存检测结果的路径和名称 。
存在性确认
`--exist-ok` 参数确定是否覆盖已存在的项目/名称目录 。
边框厚度
`--line-thickness` 参数定义了绘制边框的厚度 。
隐藏标签和置信度
`--hide-labels` 和 `--hide-conf` 参数用于在可视化时隐藏标签和置信度 。
使用 FP16 推理:
`--half` 参数允许使用 FP16 半精度进行推理,以提高速度 。
使用 OpenCV DNN:
`--dnn` 参数用于 ONNX 推理时使用 OpenCV DNN 后端 。可以提高在cpu推理速度(yoloest) PS D:\czWorkSplace\Python\yolo\yolov5> python .\detect.py
detect: weights=yolov5s.pt, source=data\images, data=data\cat.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_csv=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 db125a2 Python-3.8.18 torch-2.2.1+cu121 CUDA:0 (NVIDIA GeForce GT 1030, 2048MiB)
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.4 GFLOPs
image 1/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (1).jpg: 640x384 1 cat, 46.3ms
image 2/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (10).jpg: 640x384 1 cat, 46.9ms
image 3/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (11).jpg: 640x384 1 person, 2 cats, 46.9ms
image 4/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (12).jpg: 640x384 1 cat, 1 tv, 46.9ms
image 5/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (13).jpg: 640x384 1 cat, 1 tv, 1 keyboard, 46.9ms
image 6/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (2).jpg: 640x384 1 cat, 62.5ms
image 7/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (3).jpg: 384x640 2 cats, 52.9ms
image 8/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (4).jpg: 384x640 2 cats, 1 bed, 46.9ms
image 9/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (5).jpg: 640x384 2 cats, 62.5ms
image 10/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (6).jpg: 480x640 1 cat, 78.1ms
image 11/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (7).jpg: 640x384 1 person, 1 mouse, 60.6ms
image 12/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (8).jpg: 640x384 1 cat, 1 microwave, 58.8ms
image 13/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (9).jpg: 640x384 1 cat, 1 mouse, 1 keyboard, 43.4ms
Speed: 0.5ms pre-process, 53.8ms inference, 1.4ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp6应该是模型的问题,需要自己训练模型!(从成功的结果反推回来,确实是模型的问题。导入自己训练的模型来识别就正确了)
问题
- 训练报错 `NotImplementedError: Could not run 'torchvision::nms' with arguments from the 'CUDA' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build).
import torch # 调用依赖库
print(torch.__version__) # 查看pytorch版本
torch.cuda.is_available() # 查看GPU是否可用
# 可用的话再看降版本- 版本问题 卸载重装或找匹配版本
- NotImplementedError:无法使用来自“CUDA”后端的参数运行“torchvision::nms”。·问题 #1774 ·Ultralytics/Ultralytics(超溶解剂) (github.com)
- 导出模型报错
PyTorch: starting from runs\best.pt with output shape (1, 90972, 6) (14.1 MB) ONNX: export failure 1.2s: DLL load failed while importing onnx_cpp2py_export: (DLL)
- 卸载onnx 换个版本安装 1.16.1
uninstall 16.2,install 16.1
模型训练【train】
- 训练集:用于训练模型的数据集。模型通过从训练集中学习,调整其内部参数,以最小化预测误差。训练集是模型学习的基础,其大小和质量直接影响模型的性能。
- 验证集:用于在训练过程中评估模型性能的数据集,但不参与训练。验证集的主要作用是帮助选择最佳的模型参数和超参数,防止模型过拟合。通过在验证集上评估模型,可以在不接触测试集的情况下调整模型,从而避免在最终测试中引入偏差。 训练集训练之后,使用验证集来验证,如果合格就完成训练,不合格继续训练
python train.py python train.py --weights ./models/yolov5m.pt --data ./data/locate.yaml --imgsz 1600 --batch-size 6
python detect.py --weights ./runs/train/exp22/weights/best.pt --data ./data/locate.yaml --imgsz 1280 --source ./data/images/ll 需要注意几点
- 1.训练的配置文件指向训练的数据集路径是否正确
- 2.下载的字体可能没权限写入文件,可以直接下载扔进去
训练参数
-weights # 指定预训练权重文件*
-cfg # 模型结构文件,一般使用了weights权重文件就不用设置这个
-data # 数据集配置文件路径 就是你训练的数据集位置、label名称*
-hyp # 超参数配置文件(大量参数的配置信息)
-epochs # 训练迭代次数
据集配置:
*`--data`:指定数据集配置文件的路径,该文件描述了数据集的结构、类别等信息 。
*`--imgsz` 或 `--img` 或 `--img-size`:设置训练集和测试集的图像尺寸大小 。(图像小能加快训练速度,但是会影响输出精度,图像大需要更大的内/显存,有助于学到更多特征,可以泛化学习多种尺寸。需要平衡尺寸;2的指数)
模型配置:
`--cfg`:指定模型配置文件的路径,该文件描述了模型的结构、层数、锚点尺寸等参数 。
*`--weights`:指定预训练模型的权重文件路径,使用预训练模型可以加速训练过程并提高模型性能 。
训练配置:
*`--epochs`:训练的总轮数。(需要适合的次数,可以看曲线图分析)
*`--batch-size`:每个批次中的图像数量,较大的批次可以提高训练速度,但也可能增加内/显存消耗 。
`--lr`:学习率,决定了模型在训练过程中的参数更新步长 。
日志和可视化
`--save_dir`:保存训练过程中生成的模型权重、日志和可视化文件的目录 。
`--print_freq`:每多少批次打印一次训练信息,较小的值可以提供更详细的训练过程信息 。
其他配置:
`--rect`:设置矩阵的训练方式,最小填充,减少不必要的冗余,加速模型训练速度 。
`--noautoanchor`:关闭自动计算锚框功能,YOLOv5 采用 kmeans 聚类算法来计算 anchor box 的大小和比例 。
`--evolve`:使用超参数优化算法进行自动调参,采用遗传算法对超参数进行优化 。
设备和训练方式:
`--device`:选择训练使用的设备,CPU 或者 GPU,可以指定具体的 GPU 编号 。
`--multi-scale`:开启多尺度训练,训练过程中每次输入图片会放大或缩小一定比例 。
高级选项:
`--local_rank`:用于分布式训练,指定使用的 GPU 编号 。
`--seed`:设置训练使用的全局随机种子,保证结果的可复现性 。训练流程
train: ../datasets/cat/images/train
val: ../datasets/cat/images/train
nc: 2
names: ["kimi", "milky"]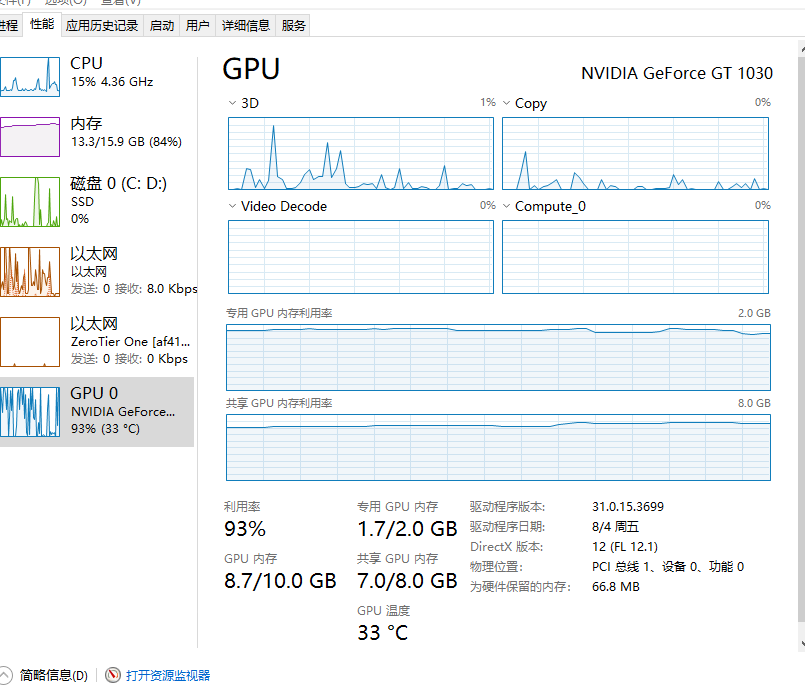
训练输出
(yoloest) PS D:\czWorkSplace\Python\yolo\yolov5> python .\train.py
train: weights=yolov5s.pt, cfg=, data=data\cat.yaml, hyp=data\hyps\hyp.scratch-low.yaml, epochs=100, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, evolve_population=data\hyps, resume_evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs\train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest, ndjson_console=False, ndjson_file=False
github: up to date with https://github.com/ultralytics/yolov5
YOLOv5 db125a2 Python-3.8.18 torch-2.2.1+cu121 CUDA:0 (NVIDIA GeForce GT 1030, 2048MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Comet: run 'pip install comet_ml' to automatically track and visualize YOLOv5 runs in Comet
TensorBoard: Start with 'tensorboard --logdir runs\train', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=2
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 18879 models.yolo.Detect [2, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model summary: 214 layers, 7025023 parameters, 7025023 gradients, 16.0 GFLOPs
Transferred 343/349 items from yolov5s.pt
AMP: checks failed , disabling Automatic Mixed Precision. See https://github.com/ultralytics/yolov5/issues/7908
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias
train: Scanning D:\czWorkSplace\Python\yolo\yolov5\datasets\cat\labels\train... 22 images, 2 backgrounds, 0 corrupt: 100%|██████████| 24/24 [00:05<00:00, 4.60it/s]
train: New cache created: D:\czWorkSplace\Python\yolo\yolov5\datasets\cat\labels\train.cache
val: Scanning D:\czWorkSplace\Python\yolo\yolov5\datasets\cat\labels\train.cache... 22 images, 2 backgrounds, 0 corrupt: 100%|██████████| 24/24 [00:00<?, ?it/s]
AutoAnchor: 3.55 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset
Plotting labels to runs\train\exp8\labels.jpg...
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to runs\train\exp8
Starting training for 100 epochs...
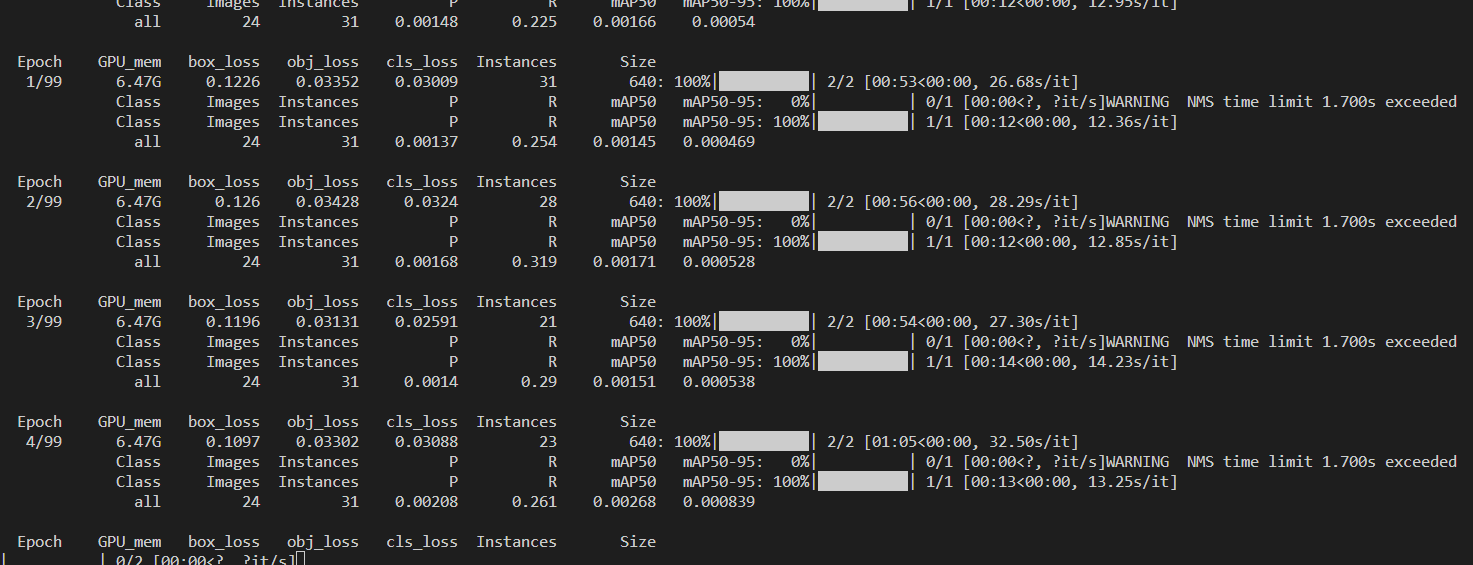
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0/99 6.12G 0.125 0.03286 0.03464 19 640: 100%|██████████| 2/2 [01:24<00:00, 42.25s/it]
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/1 [00:00<?, ?it/s]WARNING NMS time limit 1.700s exceeded
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:12<00:00, 12.95s/it]
all 24 31 0.00148 0.225 0.00166 0.00054
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
1/99 6.47G 0.1226 0.03352 0.03009 31 640: 100%|██████████| 2/2 [00:53<00:00, 26.68s/it]
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/1 [00:00<?, ?it/s]WARNING NMS time limit 1.700s exceeded
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:12<00:00, 12.36s/it]
all 24 31 0.00137 0.254 0.00145 0.000469
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
2/99 6.47G 0.126 0.03428 0.0324 28 640: 100%|██████████| 2/2 [00:56<00:00, 28.29s/it]
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/1 [00:00<?, ?it/s]WARNING NMS time limit 1.700s exceeded
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:12<00:00, 12.85s/it]
all 24 31 0.00168 0.319 0.00171 0.000528
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
3/99 6.47G 0.1196 0.03131 0.02591 21 640: 100%|██████████| 2/2 [00:54<00:00, 27.30s/it]
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/1 [00:00<?, ?it/s]WARNING NMS time limit 1.700s exceeded
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:14<00:00, 14.23s/it]
all 24 31 0.0014 0.29 0.00151 0.000538
...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
99/99 6.48G 0.03595 0.02609 0.01856 30 640: 100%|██████████| 2/2 [00:48<00:00, 24.40s/it]
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:12<00:00, 12.04s/it]
all 24 31 0.511 0.926 0.722 0.517
100 epochs completed in 1.836 hours.
Optimizer stripped from runs\train\exp8\weights\last.pt, 14.4MB
Optimizer stripped from runs\train\exp8\weights\best.pt, 14.4MB
Validating runs\train\exp8\weights\best.pt...
Fusing layers...
Model summary: 157 layers, 7015519 parameters, 0 gradients, 15.8 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:06<00:00, 6.84s/it]
all 24 31 0.496 0.893 0.719 0.513
kimi 24 14 0.427 0.786 0.655 0.484
milky 24 17 0.564 1 0.783 0.542
Results saved to runs\train\exp8比较重要的三个参数: box_loss:box回归,接近原框 obj_loss:置信度损失 cls_loss: 标签分类损失 total 前三个值的和 损失值线性下降,越低越好
输出模型 权重参数
best.pt:保存训练中参数最好的一次,用来使用 last.pt:保存训练的最后一次,用来下次接着训练
使用训练的模型识别
输出的模型 
修改配置,将输出的模型放到识别模块中去
def parse_opt():
"""Parses command-line arguments for YOLOv5 detection, setting inference options and model configurations."""
parser = argparse.ArgumentParser()
parser.add_argument("--weights", nargs="+", type=str, default=ROOT / "best.pt", help="model path or triton URL")
parser.add_argument("--source", type=str, default=ROOT / "data/images", help="file/dir/URL/glob/screen/0(webcam)")
parser.add_argument("--data", type=str, default=ROOT / "data/cat.yaml", help="(optional) dataset.yaml path")
...执行识别
(yoloest) PS D:\czWorkSplace\Python\yolo\yolov5> python .\detect.py
detect: weights=best.pt, source=data\images, data=data\cat.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_csv=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 db125a2 Python-3.8.18 torch-2.2.1+cu121 CUDA:0 (NVIDIA GeForce GT 1030, 2048MiB)
Fusing layers...
Model summary: 157 layers, 7015519 parameters, 0 gradients, 15.8 GFLOPs
image 1/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (1).jpg: 640x384 1 milky, 46.9ms
image 2/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (10).jpg: 640x384 (no detections), 49.5ms
image 3/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (11).jpg: 640x384 2 milkys, 46.9ms
image 4/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (12).jpg: 640x384 1 milky, 46.9ms
image 5/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (13).jpg: 640x384 1 milky, 46.9ms
image 6/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (2).jpg: 640x384 1 milky, 62.5ms
image 7/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (3).jpg: 384x640 2 milkys, 62.5ms
image 8/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (4).jpg: 384x640 1 kimi, 2 milkys, 46.9ms
image 9/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (5).jpg: 640x384 2 milkys, 62.5ms
image 10/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (6).jpg: 480x640 1 milky, 62.5ms
image 11/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (7).jpg: 640x384 (no detections), 46.9ms
image 12/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (8).jpg: 640x384 (no detections), 46.9ms
image 13/13 D:\czWorkSplace\Python\yolo\yolov5\data\images\a (9).jpg: 640x384 1 milky, 62.5ms
Speed: 0.0ms pre-process, 53.1ms inference, 2.4ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp7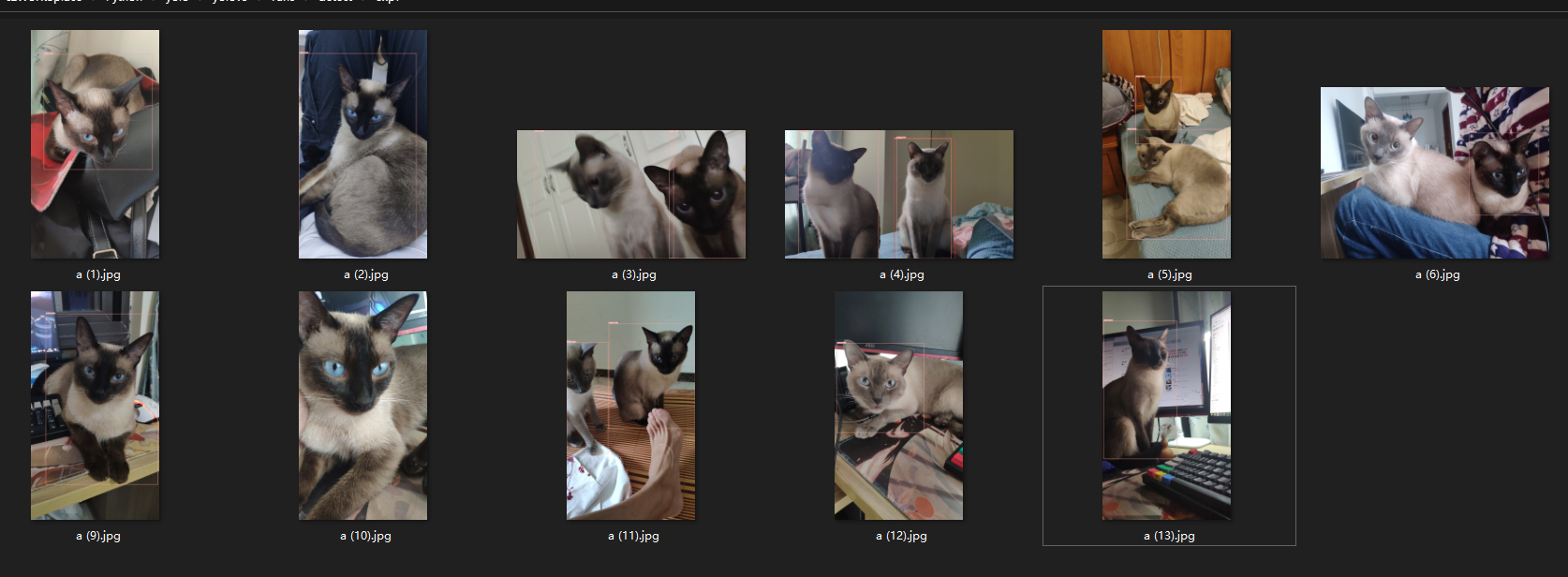
训练的图像尺寸很关键,训练样本尺寸大小/32+1*32 识别时的尺寸太小可以加快识别速度,但是结果不准确
导出转换模型【export】
python ./export.py --weights ./runs/best.pt --img 1216 --include onnx
(yolov5) E:\yolov5>python ./export.py --weights ./runs/train/exp22/weights/best.pt --img 1280 --include onnx engine --device 0
export: data=E:\yolov5\data\coco128.yaml, weights=['./runs/train/exp22/weights/best.pt'], imgsz=[1280], batch_size=1, device=0, half=False, inplace=False, keras=False, optimize=False, int8=False, per_tensor=False, dynamic=False, simplify=False, mlmodel=False, opset=17, verbose=False, workspace=4, nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100, iou_thres=0.45, conf_thres=0.25, include=['onnx', 'engine']
YOLOv5 2024-10-16 Python-3.12.7 torch-2.5.0+cu121 CUDA:0 (NVIDIA GeForce RTX 3060, 12288MiB)
Fusing layers...
Model summary: 212 layers, 20852934 parameters, 0 gradients, 47.9 GFLOPs
PyTorch: starting from runs\train\exp22\weights\best.pt with output shape (1, 100800, 6) (40.6 MB)
TensorRT: export failure 0.0s: No module named 'tensorrt'
requirements: Ultralytics requirement ['onnx>=1.12.0'] not found, attempting AutoUpdate...
Collecting onnx>=1.12.0
Downloading onnx-1.17.0-cp312-cp312-win_amd64.whl.metadata (16 kB)
Requirement already satisfied: numpy>=1.20 in c:\users\administrator\miniconda3\envs\yolov5\lib\site-packages (from onnx>=1.12.0) (2.1.2)
Collecting protobuf>=3.20.2 (from onnx>=1.12.0)
Downloading protobuf-5.28.2-cp310-abi3-win_amd64.whl.metadata (592 bytes)
Downloading onnx-1.17.0-cp312-cp312-win_amd64.whl (14.5 MB)
---------------------------------------- 14.5/14.5 MB 5.9 MB/s eta 0:00:00
Downloading protobuf-5.28.2-cp310-abi3-win_amd64.whl (431 kB)
Installing collected packages: protobuf, onnx
Successfully installed onnx-1.17.0 protobuf-5.28.2
requirements: AutoUpdate success ✅ 14.9s, installed 1 package: ['onnx>=1.12.0']
requirements: ⚠️ Restart runtime or rerun command for updates to take effect
ONNX: starting export with onnx 1.17.0...
ONNX: export success 16.6s, saved as runs\train\exp22\weights\best.onnx (81.1 MB)
Export complete (20.2s)
Results saved to E:\yolov5\runs\train\exp22\weights
Detect: python detect.py --weights runs\train\exp22\weights\best.onnx
Validate: python val.py --weights runs\train\exp22\weights\best.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'runs\train\exp22\weights\best.onnx')
Visualize: https://netron.app导出参数
*--weights:
- 指定预训练的 PyTorch 模型权重文件路径。
--imgsz:
- 指定模型输入图像的尺寸。由于 YOLOv5 可以处理多种尺寸的图像,这里可以指定一个尺寸,或者使用范围来表示多种尺寸。
-batch:
- 指定批处理大小。在导出时,这个参数定义了输入张量的批大小维度。
--dynamic:
- 指定是否导出动态尺寸的模型。当设置为 `True` 时,模型可以接收任意尺寸的输入。
--device:
- 指定运行脚本的设备,可以是 CPU 或 CUDA 设备。
--simplify:
- 使用 ONNX Simplifier 来简化模型图,这有助于优化模型大小和推理速度。
--opset:
- 指定 ONNX 操作集版本。操作集版本影响模型中可以使用的操作类型。
--input-dims:
- 指定输入张量的维度。通常用于指定输入图像的高度和宽度。
--output:
- 指定导出的 ONNX 模型文件名。
--yolo:
- 指定 YOLO 模型的版本,例如 `yolov5s.yaml`、`yolov5m.yaml` 等。
-cfg
- 指定自定义模型配置文件的路径。如果使用默认的 YOLOv5 配置,可以忽略此参数。
--model:
- 指定模型的 PyTorch 脚本文件路径。如果使用默认的 YOLOv5 模型,可以忽略此参数。
--img-path:
- 指定用于测试导出模型的图像文件路径。
--test:
- 运行导出模型的推理测试。
--verbose:
- 输出详细的信息。导出可能报错:```
PyTorch: starting from runs\best.pt with output shape (1, 90972, 6) (14.1 MB)
ONNX: export failure 1.2s: DLL load failed while importing onnx_cpp2py_export: (DLL)卸载onnx 换个版本安装 1.16.1 uninstall 16.2,install 16.1
.NET 识别
/// <summary>
/// 需要NET6+, 包:Yolov8.Net、OpenCvSharp4.Windows的包
/// </summary>
private void Shibie()
{
IPredictor yolov5 = YoloV5Predictor.Create("./best.onnx", new string[] { "mark" });
var image = SixLabors.ImageSharp.Image.Load("./locateorigin.jpg");
Prediction[] predictions = yolov5.Predict(image);
Mat math = new Mat("./locateorigin.jpg");
Func<Prediction[], OpenCvSharp.Rect> convert = (predictions) => new OpenCvSharp.Rect((int)predictions[0].Rectangle.X, (int)predictions[0].Rectangle.Y, (int)predictions[0].Rectangle.Width, (int)predictions[0].Rectangle.Height);
OpenCvSharp.Cv2.Rectangle(math, convert(predictions), new Scalar(0, 0, 255));
Cv2.ImShow("ad", math);
}版本区别
- yolov5
output0.Dimensions[2]为6,这是因为它预测了六个目标(六个边界框),包括x1、y1、x2、y2、得分(score)和标签(label)